
Digital Mapping Techniques '01 -- Workshop Proceedings
U.S. Geological Survey Open-File Report 01-223
Using the Proposed North American Data Model in a Distributed Database Environment
By Eric Boisvert, Annie Morin, Kathleen Lauzière, and Daniel Lebel
Geological Survey of Canada Ł Québec Geoscience Center
880 Chemin Ste-Foy
P.O. Box 7500
Québec City, Québec G1V 4C7
Telephone: (418) 654-3705
Fax: (418) 654-2615
e-mail: eboisver@nrcan.gc.ca,
amorin@nrcan.gc.ca,
klauzier@nrcan.gc.ca,
dlebel@nrcan.gc.ca
INTRODUCTION
Web digital libraries are fast becoming a medium of choice for gathering and accessing multiple geoscience datasets and knowledge bases. To a large extent however, data models and reliable tools to extract relevant information over the Web from digital geoscience information and exploration are still rare. Geoscientists want to access information intuitively and be provided with contextual knowledge bases that are at least as rich as what they are accustomed to in a physical library or document environment. Web-enabled systems have the potential to make the experience of visiting a digital library much richer, if based on scientifically sound semantic data models. The North American Data Model (NADM) is such a model and is gaining momentum at the GSC within several virtual library projects that address various aspects of NADM implementation. The NADM used in most Canadian projects is a variant of the official 4.3 version available from the Steering Committee web site (http://geology.usgs.gov/dm/). This variant of the model is variously referred to as "NADM 5.2, NADM 5.x and NADM Cordlink (Brodaric et al, 1999b). In this paper, we will only use "NADM" to implicitly refer to "Variant NADM 5.2".
Important work has been done along regional or thematic contexts, such as the Cordlink (Canadian Cordillera, http://rgsc.nrcan.gc.ca/cordlink/), GASL (Geological Atlas of the St.Lawrence, http://www.cgq-qgc.ca/gasl/), Hydrolink (Canadian Hydrogeology http://www.cgq-qgc.ca/
hydrolink/), Moose Mountain (very detailed 3D database of a small portion of the Canadian Cordillera foothills) and Northern Ontario (Berdusco and Boisvert, 2001). New projects led by the GSC in partnership with provincial and Territorial geological surveys are aimed at implementing a nation-wide contextual data model framework and distributed database for bedrock and surficial geology.
Within the Québec division of the GSC, we are focusing our present efforts at offering interoperability between independently constructed projects, which have led to three distinct implementations of NADM, supporting a web based Virtual Library. These three small databases are a microcosm of what is emerging as an important problem through the building of an increasing number of virtual libraries based on NADM. It is likely that more projects will consider NADM to support their data management and we will end up facing a problem of anarchic proliferation of NADM database instances and web sites. The implications of having multiple distinct databases are well known:
- for an end-user (either our clients or our own staff), a global search is generally not possible unless all databases share a common data model or dictionary, and
- for the organisation managing the data, more work is needed to maintain the data holdings and to maintain standardisation.
The obvious solution is to merge the content of all the small databases into a single database, but there are compelling reasons that preclude this approach. An interoperability approach has been used therefore, and this paper is a presentation of the challenges and possible solutions.
The prototype we wished to create had two general requirements:
- The system must permit agencies maximum flexibility. Imposing a database structure on each agency was simply not an option. Several agencies are using a proprietary database structure to support their business, and switching to another one would be too costly.
- The system must go beyond "documents" and support "feature level metadata". This means that features composing the map (which is a document) can also be documented and manipulated as valid entities. The database not only keeps information about the published document but also about the geological features displayed on the map and how these geological features are related to other features within the same document or other documents.
CENTRAL OR DISTRIBUTED?
Constraints and Options
At GSC-Québec, three NADM databases have been implemented for diverse purposes. The HYDROLINK project built a hydrogeology oriented database, a more bedrock/tectonic map repository has been initiated for GASL, while the Moose Mountain project has just begun to use NADM to store specific information about structural geology and oil and gas resources. The hydrogeology and bedrock geology communities have several common needs for content but differ in more than one aspect. If this kind of divergence is significant within a single organisation, we can imagine that it will only increase in a project undertaken by multiple organisations in different agencies. Organisations might not only differ in their practices, but also in their terminology, their jurisdictions and mandates, mapping techniques, historical backgrounds, etc. The most acute problem is "data custody". Most agencies are reluctant to relinquish management of "their" data to some centralised system as they feel they lose control over the content of their database. They are also generally reluctant to have their corporate knowledge managed and directed by another organisation, while they recognise that sharing information with the national geoscience community is very important. In the wider context of Canadian Geoscience Knowledge management (http://www.cgkn.net/), different governments, mandates, jurisdictions and objectives rule out a completely centralised system.
The physical and technological pros and cons of a centralised database are inherent issues of system architectures and have been discussed in several advanced computing papers, but these issues are somewhat external to the problem we are facing. The problem is not one of a classic client/server/hardware/software system architecture but rather a more organic problem that can be characterised as a need for a semantic framework for knowledge management. The basic problem is not "how do we consolidate distributed databases", but "how do we consolidate distributed geological knowledge and practices". The small multiple databases activity (Hydrolink, GASL and Moose Mountain) that we presented above is an excellent opportunity to examine how many repositories of geological knowledge can act in a distributed environment. The progress made so far is still exploratory and more work will be done this year to solve real life problems.
Why Not Replication?
Replication implies that each agency must maintain an exact copy of the "global" database, and changes made to one of the copies must be "replicated" in all other copies to maintain data integrity. Most RDBMS vendors allow changes to any database to be replicated to all mirrored (copies of) databases. A set of replicated databases is in fact a physically distributed database, but it acts as a centralised system, since the content of all those databases gives the user the feeling that there is only one big virtual database. This is clearly not the mechanism we want to see as we explained earlier. Although in fact some parts of the database can be exact replicas (formal time scales, mineral names, etc.), most of the content of the database is specific in either the type of content (hydrogeology versus bedrock geology) or other aspects related to jurisdiction, mandates or tradition. It is clear that all NADM databases share a certain level of commonality but we are not speaking of "exact copies" and therefore total replication is not considered further.
The alternative to full replication is "partition" where portions of the database are distributed on different servers. For example, a given database can hold time scales and another one can manage rock types. Another option is to have one database holding a subset of time scale records while the remainder are scattered among other databases (i.e. Holocene is in database A, Palaeozoic in database B and so on). This system still requires close co-ordination to avoid duplicates and inconsistency, but the overall logic is more appealing for our situation.
Semantic Interoperability
Semantic interoperability (SI) is probably the most interesting approach to distributed databases. Crudely explained, SI is a system that can translate (or restructure) on the fly information from databases having different structures and content, and can merge different result sets into a single coherent set. Although databases used in a given application domain (such as geology) may have different structures, they often have compatible content, they address the same theme and it is often possible to map the structure of one database to another, at least partially. Although this seems to be the perfect system, making two databases communicate using SI is non-trivial. The technique involves "mediators", which are software modules that solve the structural and semantic differences between databases. Although more work is required to use this approach, the benefits can greatly exceed that of other technologies.
These approaches have been weighed against the problem we wanted to solve and we built a prototype named GEOMDB (Geoscience Multiple DataBases) to test different aspects. The semantic interoperability approach seemed to be the most promising avenue and we built a prototype (the result is mostly the work of the second author) that implements certain SI ideas.
GEOMDB and <X>LINK - DISTRIBUTED DATABASE PROTOTYPE
Background
The NADM variant used in this project is a generalised version of the formal 4.3 version (Johnson et al., 1998) supported by the NADM Steering Committee (http://geology.usgs.gov/dm/). The model itself can almost be seen as a metamodel because several parts of the model can be customised for different purposes. Changes to the model can then be registered in special metadata tables that can be accessed by tools such as Geomatter (Brodaric et al, 1999a, Boisvert et al., 2000) to allow on the fly customisation. The type of data that can be manipulated varies from one database to another. For our experiment, we chose two databases because of their relative maturity: HYDROLINK stores hydrogeology related maps, images and documents while GASL addresses the bedrock geology of the Saint Lawrence River region. They are both NADM variant databases customised for their specific domains. Some attributes are shared between databases, such as rock type and geochronology, but each database requires particular attributes that have limited usage for the other. For instance, Hydrolink has a specialised table that contains conductivity values for different aquifers. Even for similar attributes, such as rock type, slight variations exist between both implementations. Both teams used the same basic dataset but customised it to fit their particular needs. Map unit types also significantly differ and the tree structure of Compound Object Archive (COA) that lives at the heart of the NADM structure is built according to different mapping traditions and logical organisations, even though the more general concepts are shared. This example illustrates two databases that address two different issues but partially overlap on certain themes. The database structure is not the only impediment to the construction of a "single global database".
GEOMDB developed at GSC-Québec as a prototype is a distributed model search engine and data extraction system that relies on the NADM COA tree to synchronise information between databases. The system requires a "global database" and a series of local databases. The communication between the global database and local ones is done by an HTTP based mediator (by exchange of HTML files), so a database can be located virtually anywhere (we are of course toying with the idea of using XML as an exchange mechanism). The client accessing the global database is in fact unaware of the interaction with distributed databases from which he will extract information (figure 1).
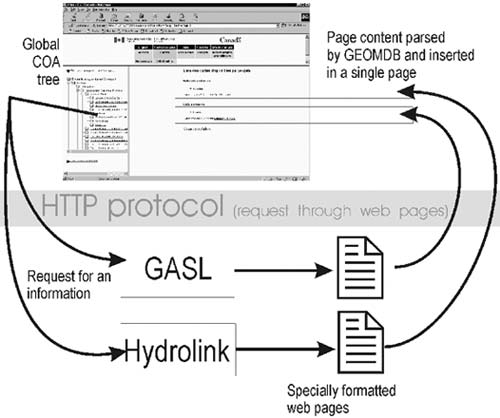
Figure 1. Merging information from several NADM sources. The HTML text sent to GEOMDB is merged back into a single web page.
|
The mediator module has been developed in Allaire ColdFusion. Our set up consists of MS Access databases on different servers, and all servers are equipped with a ColdFusion Server and an appropriate web server software (IIS on one server and Apache on the other).
Global Database Set Up
The global database is a stripped down NADM database (figure 2) that contains only COA and Subject tables and associated tables (tree, lookups, and attributes). The database also contains a list of local databases that are "registered" to provide services. Metadata about each local database are maintained on the global database. The COA and subject database together are uniquely identified with Global Unique IDs (GUID). (A subject table was added in the v 5.2 of NADM to link to the Georef classification scheme). A GUID is a long binary sequence (16 bytes) that is generated by an algorithm that guarantees that this value cannot ever be generated twice. Unique values generated by this procedure are of the form {7DD18D50-3F04-11D5-BF80-0001022439EA}. If you ever peeked into your Windows registry base, this should look familiar. The value is a mixture of network card ID, Universal Time, and other arbitrary parameters that ensure its uniqueness at the global system level. All COA records in the global database have this kind of ID.
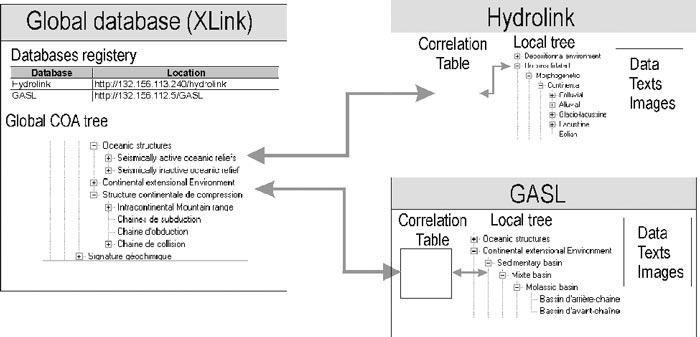
Figure 2. Small distributed system set up. The global database is a trimmed down version of NADM 5.2 containing only a global COA tree and themes with related information. Local databases have their own trees that are both a subset of the global tree (limited by the geoscience domain) but can also contain more precise definitions as extensions of the global tree. A correlation table maintains a correspondence between local and global entries.
|
Local Database Set Up
Local databases are regular NADM databases. On the local server is a series of Cold Fusion templates (mediation modules) that can be requested by the global server. The pages are specially formatted to be parsed by the server upon reception. At this point, it is possible for the local database administrator to alter the templates to adjust to small variations in database implementation (for example, one local database could use version 4.3 of NADM, or any other database structures). The global database only expects to receive the answer in the correct format (whatever the content) and assumes the local database understands the NADM ontology. Within the local database, a special table holds the correlation between the local COA values and the global equivalence. The content of the local COA tree is not a copy of the global tree; the local database administrator simply defines his local COA record to be equivalent to a particular global COA record.
Table 1 shows an example of such a correlation table. This table makes a parallel between "globally" known concepts (global COA) and local representation in the database. Of course, the local database can have more data items to fulfil its organisation's needs than the global database. The only requirement for the local database is to maintain compatible trees. A compatible tree is a tree where all parent-child relations at the local level are the same as the ones defined at the global level (see figure 3). More items can be inserted in the tree, or a global item can also be "missing" (an intermediate item is found in the local tree but does not have any linkage to a global concept), but no item can be inverted. For example, an organisation can simply forget about the Supergroup level because it is not recognised as a formal unit in this organisation. Other units can be used in local classifications while they are not recognised at the global level (the term assemblage is an example in the Québec local database on figure 4).
|
Table 1. Example of correlation (mapping) between locally identified COA and their global equivalent.

|
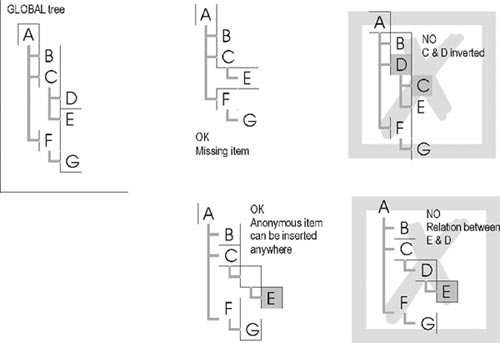
Figure 3. Example of "compatible trees". The global tree is the tree everyone agreed to. Other trees are various legal and non-legal variations of the same tree.
|
|
|
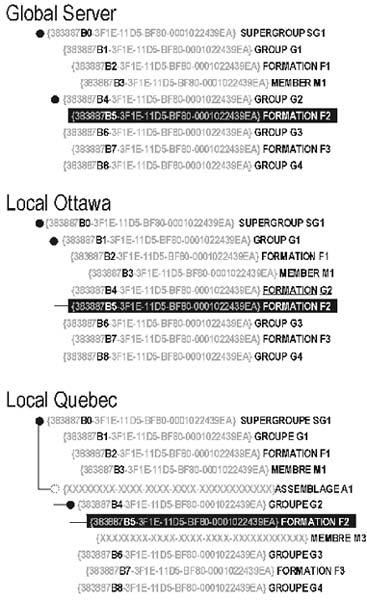
Figure 4. Tree structure used in the information exchange dialogue. The Ottawa tree shows a non compatible branch where the parent of Formation2 is not the one expected (should be Group2). The Quebec tree also shows uses "anonymous" items inserted in the tree (Assemblage 1 and Member 3), not recognised at the global level.
|
Another tree based on geoscience themes (extracted from GeoRef) is organised the same way and the technique can also be used with themes instead of COA. The theme tree has been introduced into NADM by the Cordlink project team. Themes are used to classify sources, images and texts using the logic of a library and facilitate the navigation of the Cordlink web site (and its clones, such as Hydrolink and GASL). So far, all our NADM implementations use exactly the same tree, making replication a more suitable technology for themes.
How the System Works
The user accessing the site can select from either a COA tree or a Subject tree. The COA tree structure lists all geological concepts while the subject tree lists themes (a theme can group several geological concepts while concepts can be part of several themes). The trees displayed to the user are coded with GUID. When an item is chosen, GEOMDB checks its database to identify all distributed databases it can forward the request to (Database registry of figure 2). The GEOMDB web site requests all local web sites for the required pages using the GUID selected by the user. The local mediator (Cold Fusion page) uses the correlation table to map this GUID to some local id and when a match is made, which is not always the case, requested information is extracted from the database in a specific format. The report is then parsed and merged to a single page by the global system. Different sets of reports are created for different purposes. So far we have pages that request documents, maps, and images from different servers and plan to add more data related features (age, rock unit description, etc.).
An example of a system dialog (over the future Canadian Geoscience Knowledge Network?) might translate in everyday language as follows:
Global:
Guys.. do you have anything related to {7DD18D50-3F04-11D5-BF80-0001022439EA} ?
Local Ottawa:
Yes, I've got 45 entries and 89 children items.(an entry can be a document, an image or a map)
Local Halifax:
No.
Local Québec:
Yes, I've got 34 entries and 15 children items.
Global:
(the global system now tests this part of the tree structure)
Is the tree structure (parent to child) equivalant to?
>{7DD18D54-3F04-11D5-BF80-0001022439EA}
>{7DD18D53-3F04-11D5-BF80-0001022439EA}
>{7DD18D52-3F04-11D5-BF80-0001022439EA}
>{7DD18D51-3F04-11D5-BF80-0001022439EA}
>{7DD18D50-3F04-11D5-BF80-0001022439EA}
At this point, the global system sends a complete branch (from the root up to the terminal leaf) to check if all parent-child relationships are "compatible".
Local Ottawa:
Oops, No, I have a problemŖ will send a message to our DBA.
Local Québec:
Yes, and have intermediate entries, but the tree is equivalent.
Global:
Guys, please send report about source (get_source.cfm)
Global to client
>Found 134 references (45 are exactly what you are looking for) in Ottawa but there might be inconsistencies
>Found 49 references (34 are exactly what you are looking for) in Québec.
Here's the list [. . .]
(display the list on browser):
GEOMDB then sends the information to the client browser. At this point, GEOMDB merges back the information from various servers into a single page (figure 1). GEOMDB parses the result and creates links to further explore the database. The exact content returned by the local databases is not restricted and can of course contain links back to specific information maintained in the local database. GEOMDB does not expect the remote database to be NADM compliant, but only establishes "contracts" with the remote database using mediation code. GEOMDB only requires from the local database an answer for a specific request using a specific format with agreed parameters. The local database must have some mechanism to map GUID to local concepts.
This system offers interesting possibilities: NADM, being able to offer a mechanism to relate pieces of information together, is the start of a potential knowledge base. For example, we can encode in NADM that "Dike D" cuts "Granite G" and establish a relative age between concepts. This kind of relationship might only be encoded in a single database, but since both Dike D and Granite G are correlated to some global COA, this information can then be used at the global level as "shared knowledge".
LET'S DREAM
Figure 5 is a dream scenario: Imagine a typical geological map in shape format. The shape file has a special field (called CGKN_GUID) that represents a COA. A special tool can be customised to query the global server, to search for information about specific geological features. In this example on figure 5, the user was wondering if any relationship has been observed between this specific dike and a granite, but other information can be extracted as well. Maybe the Ottawa database has a list of geochronological ages for this granite and a student in Québec dated the dike and this information can be extracted back to confirm (or deny) the explicit relation made in the Halifax database.

Figure 5. Dream application. The global (GEOMDB) can act as a "service" that can deliver geoscience information to various datasets. Each feature on the map has a GUID that can be used to fetch information from distributed sources. In this example, the global system has been asked to find information about the relationship between two features and in turn forwards the query to all registered databases. One of the databases could send back information to the global system which returns it to the client application.
|
LOOKS LIKE A METADATA SERVER TO ME!
This is a metadata driven system. A good part of NADM is in fact a feature level metadata system. Unlike FGDC, it does not work with a list of keywords to find the information but relies on strictly defined features (identified with GUID) that lie within the document to be searched. This system would not be impossible to create using other metadata manager systems but an NADM based system has the benefit of also being the database we would use to store our maps and related information (instead of maintaining separate databases) and provides the ontology for the system. A reasonable portion of NADM can be mapped directly to the FGDC metadata profile, and attempts to map a subset of the FGDC profile are underway.
CONCLUSION
The work done for the GEOMDB is very preliminary but it already shows great potential for a larger implementation. We can see at least three benefits of using this architecture:
- An improved way to map complex (hierarchical) information into a coherent global infrastructure while maintaining a customised local nomenclature.
- A way to link several pieces of information, such as rock unit descriptions, ages, documents, or images to one or more classification schemes (COA or Thematic). The COA (or Theme) can be seen as a "bucket" containing different pieces of information (Nelson et al., 1999; Maly et al. 1999).
- A way to create a knowledge based classification scheme. NADM offers a powerful structure to manage relations between COA items and create an "information space" (Feng et al.2001 Ł see figure 2)
In future work, we will explore how to implement the "dream system", but results so far are encouraging. The technology required is relatively simple since it uses a regular web server and inexpensive dynamic web generation tools (Cold Fusion, ASP, PHP (Apache), etc).
ACKNOWLEDGMENTS
Gratitude is expressed to Dave Soller (USGS) and Peter Davenport for improving this paper. Special thanks to John Broome for finding necessary funds to attend DMT 2001.
REFERENCES
Berdusco, B., and Boisvert, E. , 2001, Building a digital map with Geomatter II at the Ontario Geological Survey (Poster): Geological Association of Canada Ł Mineralogical Associtation of Canada joint meeting, May 2001. St-John's Newfoundland, Canada, http://gis.geosurv.gov.nf.ca/GAC_2001/seven/sub_program.asp?sess=98&form=10&abs_no=618.
Boisvert, E., Desjardins, V., Brodaric, B., Berdusco, B., Johnson, B., and Lauzière, K., 2000, Geomatter II: A Progress Report, in D.R. Soller, editor, Digital Mapping Techniques '00 - Workshop Proceedings; U.S. Geological Survey Open-File Report 00-325, p. 87-95, https://pubs.usgs.gov/openfile/of00-325/boisvert.html.
Brodaric, B., Boisvert, E., and Lauzière, K., 1999a, Geomatter: A Map-Oriented Software Tool for Attributing Geologic Map Information According to the Proposed U.S. National Digital Geologic Map Data Model, in D.R. Soller, editor, Digital Mapping Techniques '99 - Workshop Proceedings; U.S. Geological Survey Open-File Report 99Ł386, p. 101-106, https://pubs.usgs.gov/openfile/of99-386/brodaric2.html.
Brodaric, B., Journeay, M., Talwar, S., and Boisvert, E., 1999b, Cordlink Digital Library. Geological Map Data Model, Version 5.2, June 18, 1999 http://132.156.108.208/Cordlink1/.
Feng, L., Jeusfeld, M.A., and Hoppenbrouwers, J., 2001, Towards Knowledge-Based Digital Libraries: SIGMOD (Special Interest Group on Management of Data) Record, March 2001, http://www.acm.org/sigs/sigmod/record/, http://citeseer.nj.nec.com/408336.html.
Johnson, B.R., Brodaric, B., Raines, G.L., Hastings, J., and Wahl, R., 1998, Digital Geological Map Data Model 4.3: unpublished document of Association of American State Geologists / U.S. Geological Survey Data Model Working Group, http://ncgmp.usgs.gov/ngmdbproject/.
Maly, K., Nelson, M.L., and Zubair, M., 1999, Smart Objects, Dumb Archives, A User centric, Layered Digital Library Framework: D-Lib Magazine, March 1999, Vol. 5, Issue 3.
Nelson, M.L., Maly, K., Zubair, M., 1999, SODA: Smart Objects, Dumb Archives: Proceeding of the third European Conference on research and Advance Technology for Digital Library, Paris, France, September 22-24, 1999., p. 453-464.
RETURN TO Contents
National Cooperative Geologic
Mapping Program | Geologic Division |
Open-File Reports
U.S. Department of the Interior, U.S. Geological Survey
URL: https://pubsdata.usgs.gov/pubs/of/2001/of01-223/boisvert.html
Maintained by David R. Soller
Last modified: 18:24:36 Wed 07 Dec 2016
Privacy statement | General disclaimer | Accessibility