Kentucky Geological Survey
228 Mining and Mineral Resources Bldg.
University of Kentucky
Lexington, KY 40506-0107
Telephone: (859) 257-5500
Fax:
e-mail: (859) 257-1147jerryw@kgs.mm.uky.edu
The format of map descriptions as text and graphics is not conducive to easy compartmentalization in data structures. A central problem of converting descriptive prose to database formats is determining precisely what each descriptive element refers to. This requires an analysis of the map's components and how they can be represented in a database. Some descriptions refer to specific spatial objects or groups of objects in a map database (i.e., digitized features), while others apply only to abstract concepts (e.g., unmapped subdivisions of a formation). Characteristics of geologic map units found in other reports or databases also give rise to the possibility of multiple descriptions for the same geologic features. Although this is not a significant difficulty for database storage, multiple descriptions can be confusing for the end user.
The language of map description, especially lithologic terminology, presents interesting challenges for map database design. Current efforts at standardizing scientific language will be useful for future data collection; however, historical data are characterized by a diverse, nonstandardized language. Successful data model designs will have to provide mechanisms for treating such information.
This paper discusses elements of map description that relate to data model development. The ideas evolved from the ongoing task of converting Kentucky's existing geologic maps into database format. These maps contain over 10,000 individual text descriptions for geologic units that were prepared by a wide variety of authors. Converting these descriptions into database format and relating them to geologic map features is challenging due to the high variability of format and grammar of the text. The paragraphs contain a large element of lithologic description and this paper discusses methods of treating this information for both historical and newly collected data. These observations are based on past experience with creating core-logging manuals for sedimentary rocks in the coal fields of the United States.

Figure 1. Example map unit description from the Lancaster 7.5-minute quadrangle, Kentucky. |
Inspection of paragraphs on almost any map reveals a number of issues that relate to database development. Not every cartographic map unit has a single description whereas some descriptions have no cartographic representation. Figure 2 shows examples of descriptions that have no spatial representation. Subdivisions of geologic units are often described but not mapped, and they may be formal or informal. In Figure 2, the Reba Member has two separate descriptions for its lithologically distinct upper and lower parts (informal units). Remaining formal members each have a single description, but were also not cartographically depicted on the map. In this example, the map unit (Ashlock Formation) has no unique description except for the composite descriptions of its formal and informal members. As map units may have components, each constituent lithology may also have descriptive components. Figure 3A shows the heterolithic character of typical eastern Kentucky geologic units (map-unit components). Figure 3B indicates that some of the lithologies also have distinct components, which is an important design issue for encoding rock composition.
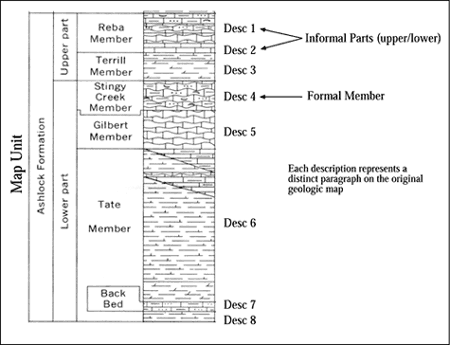
Figure 2. Formal and informal descriptive components of map units. |

Figure 3. Map-unit and lithology components for heterolithic units. A. Lithologically heterogeneous map unit. B. Heterogeneous lithology. |
Another challenge in designing the database for Kentucky geologic maps relates to map compilations. When maps have been digitally combined from multiple sources to prepare new products, revised descriptions are also compiled for the aggregated map areas. This results in multiple descriptions for the same geologic features in the map database (i.e., one for the original published map and another for the compilation). In most cases descriptive "versions" relate to maps compiled at different scales, but could also result from different authorship at the same scale.
An important aspect of such map-unit properties is that many are expressed as ranges or multiple values rather than as discrete values.
Geologic features that have more than one description (e.g. derived from two versions of a map, or two scales of compilation) present problems for user interfaces. For example, if a selected map unit has more than one lithologic description, the software system should have a rule set for determining which to return to a user's request. One means of establishing these rules is to assign a rank to descriptions that would indicate preferred data. Ranking could be based on scale, where attributes derived from larger scales would have a higher rank. Ranking descriptions could also permit the design of methods for returning information appropriate to a users' map extent or selection set. This issue will become increasingly important as seamless databases are constructed from multiple source maps.
Some of the concepts found in the Kentucky descriptions (and presumably other geologic maps) would require the addition of new data model tables. Examples are exposure conditions and engineering properties. Current implementations of the data model store much of the lithologic information in a single table. The prevalence of range data (e.g., minimum and maximum thickness) and the potentially large number of parameters suggests that individual tables for each property would be more suitable. Data model implementations should provide the flexibility for adding such features.
Consistent results. Any successful rock classification should facilitate repeatable results, particularly among different users. It may seem obvious to state that every practitioner should be able to look at a rock and derive the same name for it. But this is difficult to achieve because of the complexity of some classifications and difficulty in judging category boundaries. During the development of the core books, repeatability was measured by conducting trials in which a group of people were given criteria for classification categories and asked to place a number of samples in the appropriate category. If agreement was not high, the categories were reevaluated and boundaries adjusted to improve consistency. Two problems relating to definition of rock categories became apparent. First was the universal tendency to define too many categories. This resulted in users having to make fine distinctions of properties, usually without a high degree of success. For a given range of a gradational property, more than three or four subdivisions generally led to low levels of agreement.
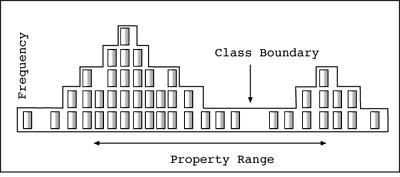
The second problem was the placement of a classification boundary within a gradational series at a naturally high frequency for a property. This could be judged because samples were taken to represent the frequency of different rock types. When arrays of samples were prepared to assess the variability of important properties (Fig. 4) distinct patterns in frequency distributions often became apparent. Placement of class boundaries at low frequency points reduced error because fewer samples would occur close to that boundary. For arrays in which there were no obvious natural boundaries, the only technique that resulted in high consistency was to keep the number of categories low. For these reasons, rock classifications that use arbitrary class boundaries inevitably result in some classes that are difficult for users to discriminate with consistent results.
|
Figure 4. Frequency distribution of a hypothetical rock-property based on systematic sampling. Sample array shown for set of core samples. |
Standard information. The core-book project was originally undertaken, in part, because previous core logs produced by drilling or coal company personnel lacked important lithologic details. Initial experiments to improve logging used experienced geologists to collect the descriptive information. These efforts were not entirely successful because there was no uniformity about what rock properties should be included in the primary rock and which should be treated as ancillary comments. This is an important distinction because of the operators' tendency to omit comments after long periods of observation (i.e., descriptions tended to become more simple toward the end of the day). Another tendency resulted from repetitive information; if a particular property was nearly invariant, operators would discontinue recording the information over time. For example, if all sandstones in a core were "lithic" in composition, only the first few occurrences would be described as such and subsequent samples would only be described as "sandstone". Although uniformity of the intervals was understood by the operator, future users of the data would be uncertain about sandstone composition.
The solution to this problem was to build as many of the important properties into the rock term as was possible and to make it simple for the operator to record this information in a field or laboratory setting. A hierarchical system of description was created that recorded the properties in a three-digit (subsequently increased to four-digit) numeric code (Fig. 5). These codes were not arbitrarily assigned; rather, each digit had significance with respect to rock properties. For example, the first digit always recorded the primary rock group (sandstone, shale, etc), and the last records sedimentary structures. The use of the middle digit was dependant on the primary rock group. For example, the code 551 indicates a primary rock group of sandstone (first digit 5), mineral composition of quartzose (second digit 5) and crossbedded structure (third digit 1). The numeric classification was documented by full-scale color photographs that depicted the range of properties for each class. English text was assigned to the codes, based on terminology in common use in the region for which each manual was prepared. The resulting numeric logging system was easy to learn and encouraged the recording of detail, because recording 541 (crossbedded lithic arenite) took no more effort than writing 500 (sandstone). The system did not preclude the use of generalized terms (i.e., 500 was a valid code). Many users did prefer to use a text rock term rather than a number and therefore the problem of consistent terminology could not be completely avoided.
| Figure 5. Elements of a numeric rock classification system and related properties. |

|
Flexible terminology. Regardless of how much effort is put into standardization of geologic terminology, many users in different locales and with varied training will continue to use variations of rock terms. Moreover, geologic databases must be capable of storing the large amount of historical data that has been collected using various descriptive systems. Nonstandard terminology between regions of the United States (and the world) proved to be a significant problem when the core manuals were prepared. Figure 6 shows an example of a root-penetrated rock that is known by different names in various parts of the country. In Pennsylvania, the term claystone is used for this rock, but that same term has very different usage in other regions. Rather than require users to adopt a single term with which they may be unfamiliar or uncomfortable, the core manuals retained regional terminology while maintaining a consistent numerical classification to unify descriptions. Therefore, the code "137" (or any other) always indicated the same lithology, irrespective of its geographic occurrence; photographs illustrating rock properties helped to reduce ambiguity in nomenclature.

Figure 6. Relating regional terminology through photographs and the numeric code. |
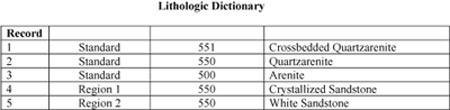
Figure 7. Generalizations (records 2-3) and synonyms (records 4-5) in a lithologic dictionary. |
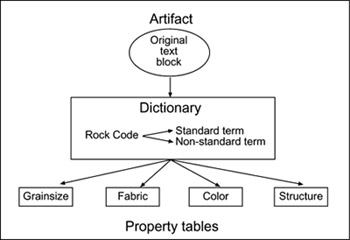
Use of a numeric code system for lithologic descriptions increases the efficiency of data collection and is well suited for processing in computer systems. Because the digits are directly related to rock properties, they can easily be linked to other tables of property names that have specified definitions and criteria. Code-based descriptions also facilitate searching of large databases for units that contain certain properties. Figure 8 illustrates a data model design that could be used for storing and retrieving lithologic descriptions. A rock description generally has a source document (published or unpublished), which can be stored in the database as a text block with appropriate metadata. Each lithology component in a description can be related to predefined classifications by associating them with an entry in a system dictionary. The dictionary consists of numeric codes with one standard and many nonstandard text names. Each lithology code will have preassigned standard rock properties that will be stored in separate description tables. Lithologies may also have nonstandard properties that could relate directly to a lithologic occurrence. For example, the rock "551" or crossbedded quartzarenite would have standard properties of grain size (sand), mineral composition (quartzose), and sedimentary structure (cross stratified). An occurrence of "551" could have a nonstandard property of carbonate cement or brittle fractures.
|
Figure 8. A sample data model design for lithologic descriptions. |
Data input for an occurrence would consist of picking the appropriate lithology code or term from the dictionary. Because each term would have pre-defined properties, users would not have to reenter that information. Queries to lithologic databases typically relate to individual properties rather than the rock terms assigned to the map unit. For example, users may desire all units with quartz-rich lithologies or those with a particular grain size. Dictionaries and related property tables will allow for efficient query tools to access lithology information in this manner.
Ferm, J.C., Weisenfluh, G.A., and Smith, G.C., in press, A method for development of a system of identification for Appalachian coal-bearing rocks: International Journal of Coal Geology, Special Publication.