|
| U.S. Deparment of the Interior
- U.S. Geological Survey |
 |
U.S. GEOLOGICAL SURVEY OPEN-FILE REPORT 00-358
|
CHAPTER
1: GRAIN-SIZE ANALYSIS OF MARINE SEDIMENTS: METHODOLOGY AND
DATA PROCESSING
|
| Poppe,
L.J.1, Eliason, A.H.2, Fredericks,
J.J.3 , Rendigs, R.R.1, Blackwood D.1 and Polloni, C.F.1 |
1Coastal and Marine Geology Program, USGS, Woods Hole, MA 02543
2 Eliason Data Services, 230 Meetinghouse Road, Mashpee, MA 02649
3Woods Hole
Oceanographic Institution, Woods Hole, MA 02543
|
INTRODUCTION
|
Grain size is the most fundamental physical property of sediment. Geologists and sedimentologists use information on
sediment grain size to study trends in surface processes related to the dynamic conditions
of transportation and deposition; engineers use grain size to study sample permeability and stability
under load; geochemists use grain size to study kinetic reactions and the affinities of
fine-grained particles and contaminants; and hydrologists use it when studying the
movement of subsurface fluids (Blatt and others, 1972; McCave and Syvitski, 1991). Therefore, with these reasons in mind, the
objectives of a grain-size analysis are to accurately measure individual particle sizes or
hydraulic equivalents, to determine their frequency distribution, and to calculate a
statistical description that adequately characterizes the sample.
The techniques and equipment used for
particle-size analysis must be fast, accurate, and yield highly reproducible results. The accuracy of these measurements is limited by
sampling techniques, storage conditions, analytical methods, equipment, and, especially, the capability
of the operator. Care and attention to detail
must be exercised to achieve the best possible results. As with most types of
sedimentological analyses
there is no ultimate technique or procedure that will produce the most desirable grain
size data for all cases. Several types of analyses have been developed over the years to
accommodate the different types and sizes of samples and the reasons for
conducting the
analysis.
 For many years,
the size and distribution of the sand and
gravel fractions were determined solely by sieve analyses, and silt and clay fractions
were determined by pipette or hydrometer methods. Later,
rapid sediment analyzers (RSA; Fig. 1; Ziegler and others, 1960; and Schlee,
1966) and electro-resistance multichannel particle-size analyzers (EMPSA; Fig. 2), such as the Coulter Counter, automated the
analysis and removed much of the
tedium from grain-size analyses. About this
same time Formula Translation (FORTRAN) programs for the calculation of statistical
parameters on geologic data also were developed (Kane and Hubert, 1962; Schlee and
Webster, 1967). Other particle-size statistical programs have since been written in
Algorithmic Language (ALGOL; Jones and Simpkin, 1970), Beginners All-Purpose Symbolic
Instruction Code (BASIC; Sawyer, 1977), and even for use with hand-held calculators
(Benson, 1981). Early attempts to integrate
computers with particle-size analysis equipment began with the settling tube (Ziegler and
others, 1964; Rigler and others, 1981), and hardware and software packages are now
available for EMPSA units (Muerdter and others, 1981;
Poppe and others, 1985; Coulter Electronics, 1989).
For many years,
the size and distribution of the sand and
gravel fractions were determined solely by sieve analyses, and silt and clay fractions
were determined by pipette or hydrometer methods. Later,
rapid sediment analyzers (RSA; Fig. 1; Ziegler and others, 1960; and Schlee,
1966) and electro-resistance multichannel particle-size analyzers (EMPSA; Fig. 2), such as the Coulter Counter, automated the
analysis and removed much of the
tedium from grain-size analyses. About this
same time Formula Translation (FORTRAN) programs for the calculation of statistical
parameters on geologic data also were developed (Kane and Hubert, 1962; Schlee and
Webster, 1967). Other particle-size statistical programs have since been written in
Algorithmic Language (ALGOL; Jones and Simpkin, 1970), Beginners All-Purpose Symbolic
Instruction Code (BASIC; Sawyer, 1977), and even for use with hand-held calculators
(Benson, 1981). Early attempts to integrate
computers with particle-size analysis equipment began with the settling tube (Ziegler and
others, 1964; Rigler and others, 1981), and hardware and software packages are now
available for EMPSA units (Muerdter and others, 1981;
Poppe and others, 1985; Coulter Electronics, 1989).
 The
commercial availability of inexpensive personal computers
allows sedimentologists to construct complete computerized particle-size analysis systems
(Poppe and others, 1985). The major advantage
of using these systems is
the time-, labor-, and cost-saving functions they afford. Most of the laboratory equipment
and procedures, and all of the data processing described herein may be adapted to
IBM-compatible personal computers.
The
commercial availability of inexpensive personal computers
allows sedimentologists to construct complete computerized particle-size analysis systems
(Poppe and others, 1985). The major advantage
of using these systems is
the time-, labor-, and cost-saving functions they afford. Most of the laboratory equipment
and procedures, and all of the data processing described herein may be adapted to
IBM-compatible personal computers.
The purpose of this chapter is to describe some of the laboratory methods,
equipment, computer hardware, and data-acquisition and data-processing software employed
in the sedimentation laboratory at the Woods Hole Field Center of the Coastal and Marine
Geology Program of the U.S. Geological Survey. The
recommendations and laboratory procedures given below are detailed, but are by no means
complete. Serious users are strongly encouraged to consult the original references and
product manuals.
FIELD METHODS
Sampling Recommendations
The results of grain-size analyses are sensitive to the manner in which the
original samples are collected, handled and stored. For
example, it is clear that the introduction of foreign particulate matter into the sample
through improper care or cleaning of equipment, or through improper processing, can alter
the texture. The growth of authigenic
minerals because of improper storage can have a similar effect and, although physical
disturbance may not generally have a direct effect on subsequent analyses, the trends of
those data may be altered if sediment layering has been disrupted. In sum, analyses that follow improper field work
may be meaningless.
To keep sampling artifacts and variation in data to a minimum, certain precautions
should be taken in the field during sampling and subsequent storage:
*
Records on sampling, including field measurements, should be painstakingly
maintained. The appropriate field
measurements and any information peculiar to the sample should be supplied to the
laboratory along with the sample.
*
Particularly in the case where the top of the sediment section is of interest, care
must be exercised during sampling. Over
penetration by sampling device and jarring or bumping during retrieval should be avoided. Surficial samples for grain size analyses are
typically defined as having been collected from 0-2 cm below the sediment/water interface.
*
If the samples are in cores with liners that need to be split, the device chosen
for cutting should not add plastic shards to the samples since contamination from these
shards affects the textural analysis. Core
halves should be stored in well-sealed D-tubes with a piece of moist Oasis or sponge to
retard evaporation. If the cores are split,
it is recommended that one half should be held in reserve as an archive until all analyses are complete
and data quality can be assured.
*
The subsamples should be stored in containers that are appropriate to the
individual analyses. Inert air-tight containers such as plastic jars, boxes, or bags are
preferable to metal cans that could rust and contaminate the sample, or cloth bags that
allow evaporation and the loss of fines.
*
All sampling utensils and containers must be clean and free of contamination. If splits of the samples are to be used for
geochemical analyses (e.g. trace metals), the sampling gear should be plastic or Teflon
coated and the containers acid washed.
*
Care must be taken to obtain a representative split when sampling in the field. Be aware of lateral and vertical variability in
grab samples. Collect larger samples from
poorly sorted sediment; smaller samples from well sorted sediment.
*
Careful labeling is critical. Labels must be legible and permanent. Test the permanency of markers prior to fieldwork.
*
To prevent geochemical reactions, the growth of organics, or evaporation from
occurring within a sample, refrigeration or freezing is necessary. Such reactions may change the mineralogy and
grain-size distributions, complicate laboratory analyses, and increase costs. For example, authigenic minerals such as gypsum
may form with individual gypsum crystals growing up to sand and even gravel-sized
particles. Similarly, excessive evaporation
must also be avoided, especially if the samples are marine and it is necessary to correct
for salt content.
*
All analyses should be performed within a reasonable (<2 months) amount of time. The longer a sample is stored, the greater the
opportunity for storage-related alteration.
Gallery of Common Sediment Sampling Devices
Grab
Samplers
Cambell Grab
Emery
and Schlee, 1963
Clamshell
Grab
Lay, 1969
Orange
Peel Grab
Lay, 1969
Petersen
Grab
Pettersson, 1928
SEABOSS
Grab
Blackwood and Parolski, 2000
Smith-McIntyre
Grab
Smith and McIntyre, 1954
Shipek
Grab
North Carolina State University, 1999
Van
Veen Grab
Lay, 1969
Corers
Alpine
Vibracorer
Sea Surveyor Inc, 2000
Electric
Vibracorer
PVL Technologies Inc, 2000
Gravity
Corer
Lee and Clausner, 1979
Hydraulically-Dampened
Corer
Bothner and others, 1997
Lamont
Box Corer
Lee and Clausner, 1979
Phleger
Corer
` Phleger,
1951
Piston
Corer
Lee and Clausner, 1979
Spade
Box Corer
Rosfelder and Marshall, 1967
Sediment
Traps
Cylindrical
Sediment Trap
Honjo and others, 1992
Time-Series Sediment Trap
McLane Research Laboratories,
2000
Dredges
Rock Dredge
Shepard, 1963
Pipe
Dredge
Shepard, 1963
Bedload
Samplers
Helley-Smith
Bedload Sampler
Emmitt, 1980
USGS
Bedload Sampler
Rickly Hydrological Company, 2000
LABORATORY PROCEDURES
Records and Metadata
.
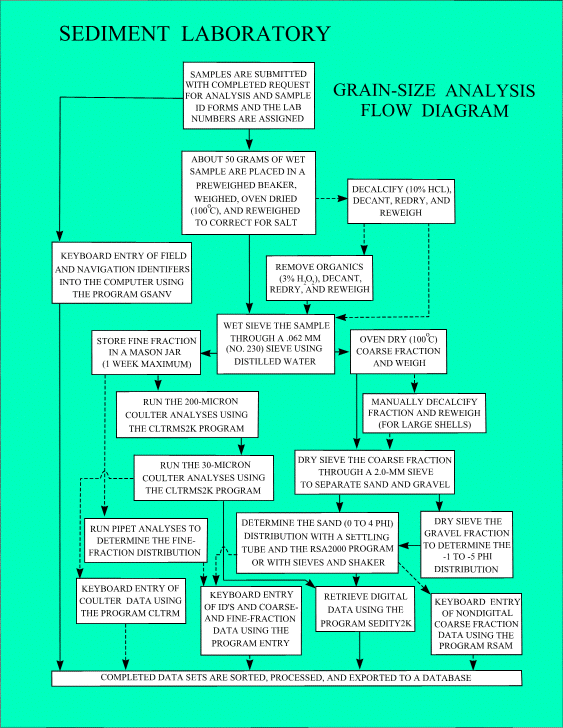
 Figure 3
outlines the laboratory techniques and software sequence of operation in a generalized
flow diagram for those procedures used in the sedimentation laboratory at the Woods Hole
Field Center. Because the size data become
part of a data base and as it is necessary to archive the raw unprocessed data, there must
be a formal system for recording sample identifiers. Appropriate identifiers include:
requestor, cruise identification (id), project id, work requested, purpose of
investigation, sample id, latitude, longitude, water depth, top-depth, bottom-depth,
sample device, sampling area, and what analyses have been completed on each sample. To this end, the use of standardized “request for analysis” and
“sample identification” forms (Figs. 4 and 5)
are recommended as organizational aids. The
completed forms should be included when samples are submitted for analysis. At this time a unique lab number should be
assigned to each sample. At the Woods Hole
Field Center, this number consists of two letters followed by three numbers (e.g. AA795). These identifiers are manually entered into a
computer using the program GSANV (Appendices A and C).
Figure 3
outlines the laboratory techniques and software sequence of operation in a generalized
flow diagram for those procedures used in the sedimentation laboratory at the Woods Hole
Field Center. Because the size data become
part of a data base and as it is necessary to archive the raw unprocessed data, there must
be a formal system for recording sample identifiers. Appropriate identifiers include:
requestor, cruise identification (id), project id, work requested, purpose of
investigation, sample id, latitude, longitude, water depth, top-depth, bottom-depth,
sample device, sampling area, and what analyses have been completed on each sample. To this end, the use of standardized “request for analysis” and
“sample identification” forms (Figs. 4 and 5)
are recommended as organizational aids. The
completed forms should be included when samples are submitted for analysis. At this time a unique lab number should be
assigned to each sample. At the Woods Hole
Field Center, this number consists of two letters followed by three numbers (e.g. AA795). These identifiers are manually entered into a
computer using the program GSANV (Appendices A and C).
Preparatory Analysis
If the whole sample is not to be used, the sample is typically split using one of
three methods: a micro-splitter, cone and quartering, or random bulk (Krumbein and
Pettijohn, 1938). Size of sample, its
homogeneity, and the degree of accuracy that is required govern which method is selected
for a given size analysis. Generally, the
larger the analyzed sample the more accurate the grain size analysis. However, unless a sample contains gravel, a 50-g
split is usually sufficient. Larger samples
are more time consuming to analyze and do not provide significantly more reliable results.
If gravel is present, the sample must contain enough material to give adequate
representation of the largest sizes present. For
example, approximately 250 g would be needed to texturally analyze a sample containing -2
phi material.
 Place the split wet sample in a pre-weighed 100-ml beaker, weigh, and record the weight on a “grain-size
analysis” form (Fig. 6). The
beakers should be scribed with a unique number and, therefore, should require no
additional labels, which would alter the weight of the beaker. Gross wet-sample weight minus the weight of the
beaker gives the net wet-sample weight. Dry
these samples in a convection oven at, or slightly below, 100 C (Fig. 7).
This temperature will only drive off unbound water and should not affect the grain size. When the samples are dry (overnight is usually
sufficient), place them in a desiccator (Fig. 7) to cool. Weigh the samples as they are
removed from the desiccator or the sample will absorb water from the air and their weights
will be less accurate. Gross dry-sample
weight minus the weight of the beaker gives the net dry sample weight; net wet sample
weight minus the net dry sample weight gives the water weight. The weight of salt can be calculated from the
salinity and the weight water. The net
dry-sample weight minus the weight salt gives the corrected sample weight. Inasmuch as the weight of fines are typically
determined by subtracting the coarse weight from the net sample weight, the salt in marine
samples must be determined to prevent an overestimation in the amount of fines present.
Place the split wet sample in a pre-weighed 100-ml beaker, weigh, and record the weight on a “grain-size
analysis” form (Fig. 6). The
beakers should be scribed with a unique number and, therefore, should require no
additional labels, which would alter the weight of the beaker. Gross wet-sample weight minus the weight of the
beaker gives the net wet-sample weight. Dry
these samples in a convection oven at, or slightly below, 100 C (Fig. 7).
This temperature will only drive off unbound water and should not affect the grain size. When the samples are dry (overnight is usually
sufficient), place them in a desiccator (Fig. 7) to cool. Weigh the samples as they are
removed from the desiccator or the sample will absorb water from the air and their weights
will be less accurate. Gross dry-sample
weight minus the weight of the beaker gives the net dry sample weight; net wet sample
weight minus the net dry sample weight gives the water weight. The weight of salt can be calculated from the
salinity and the weight water. The net
dry-sample weight minus the weight salt gives the corrected sample weight. Inasmuch as the weight of fines are typically
determined by subtracting the coarse weight from the net sample weight, the salt in marine
samples must be determined to prevent an overestimation in the amount of fines present.
Whole or fragmented calcite secreting micro- and macro-organisms can bias the grain
size distribution if they occur in significantly high concentrations. Because biogenic
carbonates commonly form in situ, they usually are not considered to be hydraulically
representative of the depositional environment from a textural standpoint (Reineck and
Singh, 1980). Their presence alters the
textural data and complicates interpretation. If
pervasive throughout the sand fraction, biogenic calcite or aragonite may be selectively
dissolved from the bulk sample using cold, dilute (10%) hydrochloric acid (HC1) or a 5-pH
Na0Ac buffer (Jackson, 1956; see section on insoluble residues below). After the carbonate has been dissolved, the HC1 or
Na0Ac can be removed with multiple decantations or centrifugations using distilled water
to remove the salts and acid and (or) buffer. If
limited to the gravel fraction, it is often easier to manually remove the fragments of
bivalve shells and other biogenic carbonate debris (see below) rather than treating the
whole sample. Care must be taken to use
dissolution techniques only when detrital carbonate is absent.
The removal of organic matter may be necessary to achieve complete dispersion of
the clay and, in sediments with an elevated organic content (>3%), to prevent the
organics from being counted as part of the sample, which would bias the grain-size
distribution. The sample is placed in a
600-ml beaker and a small volume (~10 ml) of 30% hydrogen peroxide is added. The sample is stirred and, if necessary, water is
added to slow the reaction down and prevent bubbling over.
More hydrogen peroxide is added until the dark color of the organic matter has
largely disappeared; then the sample is washed three times with a NaOAc buffer of pH 5 and
once with methanol to remove the remaining released cations (Jackson, 1956).
If the samples have been treated with acid or hydrogen peroxide, they should be
re-dried and re-weighed to recalculate the post-treatment net sample weight. Subtracting this value from the original sample
weight will determine the weight of the removed constituent.
Soluble salts and exchangable polyvalent cations can be removed by decantation or
centrifugation with distilled water to prevent flocculation of the sediment and to give
effective dispersion during pipette analysis. However,
this decantation may result in partial loss of the colloidal-clay fraction.
Wet sieve (Fig. 8) the sample through a 62-micron (American Society for
Testing and Materials (A.S.T.M). Number 230) sieve to separate the sample into coarse (sand
and gravel which are retained on the sieve) and fine (clay and silt) fractions (Fig. 9;
Tab. 1).
Distilled water (Fig. 10) is used during wet
sieving if the fine fraction comprises greater than 5% of the sample. Samples will
disaggregate more easily if allowed to soak in a small amount of distilled water or
electrolyte solution prior to wet sieving. An approximately 3-5% solution of sodium
hexametaphosphate (800 g of purified (NaPO3)6, 80 ml of formaldehyde
to retard biogenic growth, and 20 liters of distilled water) is recommended for wet
sieving if an EMPSA (e.g. Coulter Counter or Elzone) will be used in the fine-fraction
analysis and only small amounts of fines are present.
This solution acts as an electrolyte, which is necessary when EMPSAs are used.
during wet
sieving if the fine fraction comprises greater than 5% of the sample. Samples will
disaggregate more easily if allowed to soak in a small amount of distilled water or
electrolyte solution prior to wet sieving. An approximately 3-5% solution of sodium
hexametaphosphate (800 g of purified (NaPO3)6, 80 ml of formaldehyde
to retard biogenic growth, and 20 liters of distilled water) is recommended for wet
sieving if an EMPSA (e.g. Coulter Counter or Elzone) will be used in the fine-fraction
analysis and only small amounts of fines are present.
This solution acts as an electrolyte, which is necessary when EMPSAs are used. 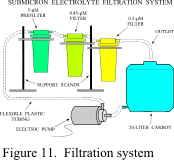 Seawater may also be used for
sample soaking and sieving purposes and as an electrolyte for the Coulter Counter as
dictated by the objectives of the specific project. A 0.5% sodium hexametaphosphate
solution should be used if the fine fraction is to be analyzed by pipette; at this
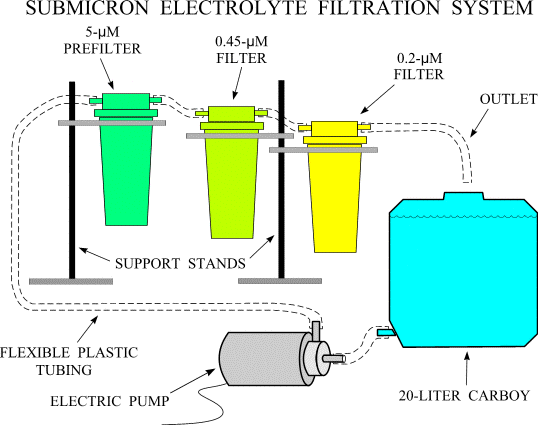
concentration, the sodium hexametaphosphate acts as a dispersant. In any case, the solution must be filtered to 0.2
microns; a sequential submicron filtration system combining 5, 0.45, and 0.2 micron
filters works well (Fig. 11). A
rubber policeman and a squeeze bottle of distilled water or the solution provide the best
sieving results. The coarser sand and gravel fractions are retained on the screen while
the finer silt and clay fractions are collected in a catch pan or mason jar. Wash the coarse fraction into a pre-weighed 100-ml
beaker and seal the fine fraction in the mason jar. Wet
sieve using only enough liquid to fit in a single 32-ounce mason jar to prevent any
possible fractional biasing of the fine fraction.
Seawater may also be used for
sample soaking and sieving purposes and as an electrolyte for the Coulter Counter as
dictated by the objectives of the specific project. A 0.5% sodium hexametaphosphate
solution should be used if the fine fraction is to be analyzed by pipette; at this
concentration, the sodium hexametaphosphate acts as a dispersant. In any case, the solution must be filtered to 0.2
microns; a sequential submicron filtration system combining 5, 0.45, and 0.2 micron
filters works well (Fig. 11). A
rubber policeman and a squeeze bottle of distilled water or the solution provide the best
sieving results. The coarser sand and gravel fractions are retained on the screen while
the finer silt and clay fractions are collected in a catch pan or mason jar. Wash the coarse fraction into a pre-weighed 100-ml
beaker and seal the fine fraction in the mason jar. Wet
sieve using only enough liquid to fit in a single 32-ounce mason jar to prevent any
possible fractional biasing of the fine fraction.
Coarse Fraction Analysis (Gravel Plus Sand)
Dry the coarse fractions in a convection oven at, or slightly under 100 C. When the samples are dry (overnight is usually
sufficient), place them in a desiccator to cool before weighing them. Gross coarse weight minus the weight of the beaker
gives net coarse weight.
Much of the biogenic calcite found in a sample is commonly in the form of coarse
pelecypod or gastropod shell fragments. Rather
than treating the bulk sample with acid, it is often easier and less time consuming to
manually remove this carbonate from the washed coarse fraction and to re-weigh the
decalcified portion to determine the new net coarse weight.
The weight of the carbonate must be subtracted from the net sample weight before
entering the data into the computer.
The grain-size distribution within the coarse fraction can be determined by use of
a settling tube (Figs. 1, 12; Schlee, 1966). However, if this fraction weighs less than 10 g or
if it contains greater than about 2% foraminifera, which will not settle properly in a
sedimentation column, then wire-mesh sieves must be employed.  If the
coarse-fraction grain-size distribution is to be determined by sieving, assemble a bank of
sieves, which generally consists of a cover, the -1, 0, 1, 2, and 3 phi sieves, and a
catch pan (Table 1; Figs. 9, 13). The bank of sieves is agitated in a shaker (Fig. 13)
for a minimum of at least 15 minutes. Although
Mizutani (1963) and McManus (1963, 1965) recommend a sieving time of 35 minutes for 8-inch
diameter sieves, Royse (1970) suggests 10 minutes as an adequate sieving time. After sieving, weigh the individual sand and
gravel phi fractions and record the weights from each phi class. Net coarse weight minus the gravel weight gives
the sand weight. If material coarser than 2 mm is present, assemble a bank of
gravel-fraction sieves (the cover, the -5 thru -2 phi sieves, and a catch pan); sieve to
separate, weigh each phi class, and record the weights.
Calculate the relative percentages of the sand-fraction phi classes and the
relative percentages of the gravel-fraction phi classes. The sieve data are normally
entered directly into a computer using the program RSAM (Appendices A, and C) to obtain a
complete grain-size distribution.
If the
coarse-fraction grain-size distribution is to be determined by sieving, assemble a bank of
sieves, which generally consists of a cover, the -1, 0, 1, 2, and 3 phi sieves, and a
catch pan (Table 1; Figs. 9, 13). The bank of sieves is agitated in a shaker (Fig. 13)
for a minimum of at least 15 minutes. Although
Mizutani (1963) and McManus (1963, 1965) recommend a sieving time of 35 minutes for 8-inch
diameter sieves, Royse (1970) suggests 10 minutes as an adequate sieving time. After sieving, weigh the individual sand and
gravel phi fractions and record the weights from each phi class. Net coarse weight minus the gravel weight gives
the sand weight. If material coarser than 2 mm is present, assemble a bank of
gravel-fraction sieves (the cover, the -5 thru -2 phi sieves, and a catch pan); sieve to
separate, weigh each phi class, and record the weights.
Calculate the relative percentages of the sand-fraction phi classes and the
relative percentages of the gravel-fraction phi classes. The sieve data are normally
entered directly into a computer using the program RSAM (Appendices A, and C) to obtain a
complete grain-size distribution.
Sieving efficiency increases with reduction in load (i.e. smaller sample size) and
the maximum sieve load diminishes with mesh size, but it is the quantity of finer
near-mesh size particles that actually determines sieving efficiency (Royse, 1970).
Twenhofel and Tyler (1941) recommended 40 g of sandy sediment as the maximum load for
8-inch diameter sieves. When selecting a procedure, it is important to remember that
sieves sort material not only according to size, but also according to the shape and
roundness of the particles (Sahu, 1965; Kennedy and others, 1985).
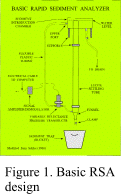
The settling tube, also called a rapid sediment analyzer (RSA, Figs. 1, 12; Zeigler and others, 1960; Zeigler and
others, 1964; Schlee, 1966, Syvitski and others, 1991) provides a means for
efficient analysis
of sand-sized material by settling the grains through a column of water. One common settling tube design is based on using
the pressure differential between two columns of water that have a common head. The pressure change caused by the introduction of
sediment within one of the columns is measured by a Validyne DP-103 variable-reluctance
wet-wet pressure transducer and amplified by a Validyne Model CD-23 frequency demodulator.
Results are relayed to a Dell Dimension personal computer equipped with an ADAC
Corporation 5500HR-1 analog-to-digital data acquisition board and associated ADLIBWIN and
ADLIBPC data acquisition software drivers. As
the sediment settles past the pressure transducer port, the pressure differential
decreases with time. Because the
sedimentation rate, in accordance with Stoke's Law (Fig. 9),
is a function of grain size, one can interpret the sand-fraction grain size distribution
from the variation in pressure differential. In addition to the settling tubes that use
pressure transducers, other devices incorporate a balance, and measure changing weight
with time as the sediment settles.
If the sand-fraction grain-size distribution is to be determined by settling tube
and the program RSA2000 (Appendices A and C), the gravel-fraction distribution, if
present, must still be determined by sieve analysis.
To use a settling tube with a pressure transducer, a warm-up and stabilization time of about an hour is required for the transducer and
associated electronics. During
warm-up the
operator should check the system pressure lines for air bubbles and the settling column
water level and turn on the computer and initialize the program RSA2000. Remove all air
bubbles from the lines; raise the water level to 3-5 mm above the actual settling tube (Figs. 1, 12). The operator has the option of selecting either of
two modes of sample introduction: an automated flipper or manually with a tablespoon (this
is generally true for most automated settling tubes).
Both methods require practice to achieve reproducibility, but the results of both
methods are equally accurate and comparable.
A micro-splitter or cone-and-quartering is used to obtain a sample of about 10 g.
Smaller samples generate too weak a signal from the pressure transducer; a weak signal may
be diluted by electrical and mechanical noise causing greater error in the reproducibility
of the data. Samples larger than 10 g are more apt to form density currents down the sides
of the settling tube or, upon introduction, to form clumps of finer sediment which act as
much larger particles.
Whether
the automated flipper or manual spoon technique is employed, the sample must be dampened
with just enough water to afford enough
inter-grain cohesion to insure simultaneous introduction of the sample, and to prevent air
from becoming trapped in the sample, which may slow the settling rate of the particles.
If
the automatic flipper technique is selected, place the sample on the flipper using a
tablespoon, flatten the top of the sample to <1 cm in height, and dampen the sample
with an eyedropper. When the switch that
controls the flipper is shifted, the sample will be introduced into the settling tube. When the flipper is halfway between the vertical
and contact with the settling tube, move the switch back to its original position. This will prevent the flipper from crashing into
the settling tube and introducing noise into the system.
The manual spoon technique simply involves placing the sample split into a
tablespoon, dampening the sample with an eyedropper, and dumping the sample in one smooth,
rapid motion from a height of about 3 cm down the center of the settling tube. If the operator misses the center and introduces
the sample near the wall of the tube, a density current that flows down the side of the
tube will form and the sample will appear to be coarser than its true distribution. The operator is encouraged to run a few standards
to check for equipment problems and practice sample introduction. This exercise will help the operator to produce
more accurate and reproducible analytical results. After
the sample has settled to the bottom of the tube and the pressure differential returns to
approximately zero, a hard copy of the
sand-fraction grain-size distribution can be generated (Fig. 14),
and the data can be saved to disk.
Fine Fraction Analysis
(Silt plus Clay)
The fine-grained fraction of a sediment is defined as silt (particles with
diameters less than 62 microns down to 4 microns; Fig. 9)
plus clay (particles with diameters less than 4 microns, with colloidal clay being less
than 0.1 microns). Because of their small size, fine-fraction particles are difficult to
measure by sieving. Therefore, the classical techniques to analyze the fine-grained
portion of grain-size distributions are dominated by sedimentation methods like the
hydrometer and pipette methods (Krumbein and Pettijohn, 1938; Milner, 1962; Folk, 1974). These methods involve preparing a dispersed,
homogeneous suspension of the fine fraction, dilution with a dispersant solution (usually
0.5% sodium hexametaphosphate) to 1000 ml, and allowing the particles to settle in a
graduated cylinder. As the settling of sediment particles continues according to
Stoke’s Law, samples are either withdrawn (pipette) or measurements made (hydrometer)
of the suspension at preset time intervals. However,
many sedimentation laboratories have discontinued or limited the use of pipette and hydrometer techniques because of inherent problems with
settling (e.g. Brownian motion), thermal convection, irregular particle shape, mass
settling in density currents, rounding errors due to large multiplication factors, and,
especially, the time necessary to extend an analysis down into the clay range. For example, over 24 hours are required to extend
a pipette analysis down to 11 phi at 20oC, room temperature (Krumbein and
Pettijohn, 1938; Milner, 1962).
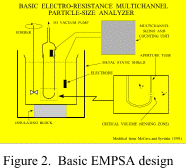
 Although originally designed
to count and size blood cells (Coulter, 1957; Berg, 1958), EMPSAs have found other
applications because of the short time and small amount of material required for analysis
(Figs.
2, 15). These
devices, which are currently manufactured by Coulter/Beckman (Coulter Counter) and
Particle Data (Elzone, now affiliated with Micrometrics), are also used in industry, in the biological sciences (Sheldon and
Parsons, 1967), and in geology, where they are used to measure the grain size of sediments
by measuring differences in electrical resistivity produced by sediment particles (McCave and Jarvis, 1973; Shideler, 1976; Kranck
and Milligan, 1979; Muerdter and others, 1981; Milligan and Kranck, 1991). Because the
aperture tubes used by EMPSAs can size particles of only 2-40% of the aperture diameter,
at least two aperture tubes with overlapping ranges are required to determine the size
distribution within the fine fraction of a marine sediment.
For example, during a standard multi-aperture analysis using a Coulter Counter, a 200-micron
aperture tube would be used to resolve the size distribution between 64 to 8 microns, and
a 30-micron aperture tube would be needed to resolve the size distribution between 12
microns down to approximately 0.5-0.7 microns. These
individual analyses or passes through the respective aperture tubes are then
mathematically combined to produce the fine-fraction (silt plus clay) distribution. The fine fraction is, in turn, combined with the
coarse fraction data to generate a complete grain size distribution.
Although originally designed
to count and size blood cells (Coulter, 1957; Berg, 1958), EMPSAs have found other
applications because of the short time and small amount of material required for analysis
(Figs.
2, 15). These
devices, which are currently manufactured by Coulter/Beckman (Coulter Counter) and
Particle Data (Elzone, now affiliated with Micrometrics), are also used in industry, in the biological sciences (Sheldon and
Parsons, 1967), and in geology, where they are used to measure the grain size of sediments
by measuring differences in electrical resistivity produced by sediment particles (McCave and Jarvis, 1973; Shideler, 1976; Kranck
and Milligan, 1979; Muerdter and others, 1981; Milligan and Kranck, 1991). Because the
aperture tubes used by EMPSAs can size particles of only 2-40% of the aperture diameter,
at least two aperture tubes with overlapping ranges are required to determine the size
distribution within the fine fraction of a marine sediment.
For example, during a standard multi-aperture analysis using a Coulter Counter, a 200-micron
aperture tube would be used to resolve the size distribution between 64 to 8 microns, and
a 30-micron aperture tube would be needed to resolve the size distribution between 12
microns down to approximately 0.5-0.7 microns. These
individual analyses or passes through the respective aperture tubes are then
mathematically combined to produce the fine-fraction (silt plus clay) distribution. The fine fraction is, in turn, combined with the
coarse fraction data to generate a complete grain size distribution.
An obvious limitation of this method is that an EMPSA, even if calibrated to
resolve down to about 0.6 microns (10.75 phi), can only resolve a portion of the clay size distribution. The fine clay in the 0.6 to 0.1 micron range (some
of the 11 phi and all of the 12 phi and 13 phi fractions that extend down to the colloidal
clay boundary) is not detected. Although an
analysis performed down to 0.6 microns is adequate for most freshwater, estuarine, and
shelf environments, the sediments from many deeper water marine environments (e.g. rise
and abyssal plain) may contain significant material in the fine clay fraction. By combining a double-point pipette analysis with
the data from an EMPSA analysis details of the fine-fraction can be extended through the
fine clay range, but this solution is less desirable because of the problems with pipette
analyses cited above and because the resultant data are no longer at whole-phi intervals.
Earlier efforts to extrapolate grain size data beyond the limits of the analysis
used graphical methods (Schlee and Webster, 1967; Schlee, 1973). For example, if Schlee determined that more than
5% of the fine-grained sediment from a sample was less than 1 micron, additional data
points were estimated for the finer sizes at whole-phi
intervals by projecting the grain-size curve as plotted on probability paper and
following the slope of the line. While this is a practical solution, it is much more labor
intensive than the computer program CLAYES2K utilized as part of this system and provided
herein.
The fine fraction, which has been stored in mason jars with distilled water or
sodium hexametaphosphate solution, may be analyzed by pipette or EMPSA. The EMPSA
determines particle volume; the pipette method measures settling rates. The reason for
performing the analyses should determine which method is used (see Comments section).
The pipette method consists of preparing a dispersed (by sonic probe), homogeneous
(by vigorous stirring) suspension of the fine fraction, dilution with a 0.5% sodium
hexametaphosphate solution to 1000 ml, and allowing the particles to settle in a graduated
cylinder (Royse, 1970; Folk, 1974). The optimum sample is approximately 20 cm3
(about 15 g dry weight). With more sample, the grains interfere with each other during
settling; with less sample, the effects of weighing errors on the analysis increase. Subsamples of 20 ml are withdrawn from
the suspension at levels at 5, 10, or 20 cm below the water surface at standard intervals
of time (Table
2A). Because all particles of' a
given equivalent diameter (based on calculations using Stoke's Law; Fig. 9)
will have settled below that level after a standard interval of time, the samples should
contain only finer particles. These aliquots
are either suction-mounted on pre-weighed filters
and rinsed in distilled water or placed in pre-weighed 100-ml beakers. If pre-weighed
beakers are used, the operator must remember to account for the weight of the dispersant
when calculating the phi-fraction weights. The
pipette is rinsed with distilled water after each extraction and the rinse water is also
passed through the filter or drained into the pre-weighed beaker with the aliquot. To begin the analysis, start the timer as soon as
the stirring rod emerges for the last time. At
the end of 20 seconds, insert the pipette to a depth of 20 cm and withdraw the precise
subsample (exactly 20 ml). Inasmuch as the
subsequent analysis is based on this subsample, this is the most important single step. If excess liquid is accidently drawn into the
pipette, do not attempt to return it to the cylinder. Remove the pipette and discard the
excess.
Continue the withdrawals at the specified time intervals and depths. The aliquots are dried and weighed, the weights
are recorded on an analysis form (Fig. 16), and the size distribution is
calculated from the weight of sediment. The
principle behind the computation is this: if the fine sediment is uniformly distributed
throughout the entire 1000-ml column by stirring, and exactly 20 ml is drawn at each of
the stated times, then the amount of mud in each withdrawal is equal to 1/50 of the total
amount of mud remaining suspended in the column at that given time and at that given depth
(i.e., the amount of mud finer than the given diameter; all particles coarser than the
given diameter will have settled past the point of withdrawal). The first withdrawal is made so quickly after
stirring and at such a depth that particles of all sizes are present in suspension.
Therefore, if we multiply the weight of the first withdrawal by 50, we will obtain the
weight of the entire amount of mud in the cylinder. Then
if we withdraw a sample at a settling time corresponding to a diameter of 6 phi, and
multiply by 50, then we know that the product represents the number of grams of mud still
in suspension at this new time, therefore the weight of mud finer than 6 phi. Similarly, we can compute the weight percent at
any size and obtain an entire distribution.
Because of the length of time required to complete a whole-phi interval analysis
(16 hours, 24 minutes to 10 phi at 20oC; Table 2A)
and because Brownian motion interferes with the settling of particles less than 10 phi,
the pipette method is now used 1) to determine the silt/clay boundary in percent
gravel-sand-silt-clay analyses and 2) when a sample contains a significant amount of
material smaller than 0.6 microns in diameter. This
latter condition is important to consider because an EMPSA determines a size distribution
based solely on the grain-size range it has been calibrated to analyze (e.g. 0.062 mm
>x>0.6 microns) and many low-energy and deepwater environments contain significant
amounts of very fine clay and colloidal clay-sized material that are undetected by EMPSAs. The time needed to perform a pipette analysis may
be reduced by placing the settling cylinders in a constant temperature bath and lowering
the viscosity of the settling, medium by increasing its temperature (Table 2B, C).
The data from a pipette analysis can be converted into frequency or cumulative
frequency percentages. These percentages can subsequently be combined with the
coarse-fraction data using the programs ENTRY to generate a complete grain-size
distribution, statistics, and database files with the program GSTATM (Appendices B and C).
To perform this silt/clay boundary analysis, aliquots are collected at 20 cm depth
after 20 seconds elapsed time to determine the concentration of sample in suspension, and at a depth of 10 cm
after exactly 2 hours and 3 minutes to
determine the concentration of clay in
solution. Because only two aliquots are collected, the size of these aliquots are usually
enlarged to 50 ml to minimize analytical error. The percentages of silt and clay can be
determined from the weight of sediment in the aliquots.
The Coulter Counter, a widely used EMPSA (Figs. 2,
15),
permits easy, fast, and accurate analysis of fine-fraction size distributions. The
instrument's optimum precision, as with all the above analyses, is realized only if the
operator is conscientious in attention to detail and consistently follows established
procedures. The following procedure is by no means complete and is intended solely as a
set of guide lines. All operators are encouraged to familiarize themselves with the
complete instrument manual to achieve the best results.
The Coulter Counter Multisizer IIe EMPSA is activated and operated according to the
following steps:
1) The main
Coulter Counter unit, sample stand, computer, and printer are turned on and allowed to
warm up for 15 minutes. Initialize the computer program CLTRMS2K (Appendices A and C).
2) Using the
menu select arrows and the numeric key pad enter the proper information. The main setup
menu should read: ORIFICE DIAMETER - 200 microns, SETUP - manual, ANALYSIS - Sample,
CALIBRATION - Recall, and SIZE UNITS - microns. The ORIFICE LENGTH, Kd, and SIZE are set
by the Multisizer.
3)
Step through the other setup screens, ensuring that the proper settings are
selected. The ANALYSIS SETUP-1 menu selections should read: CURRENT AND GAIN - Automatic,
APERTURE CURRENT - 1600 micro-Amps, GAIN - 1 or 2, POLARITY - Alternate +/-, INSTRUMENT
CONTROL - Manual, and TIME - seconds. The ANALYSIS SETUP-2 menu should read: CHANNELS -
256, AUTOSCALING - On, EDIT - Off, COINCIDENCE CORRECTION - Off, ANALYTICAL VOLUME - 0
micro-liters, PARTICLE RELATIVE DENSITY - 1.00, DIFFERENTIAL VALUES - %, and END TONE -
On. The COMMUNICATIONS SETUP screen should read BAUD RATE - 9600, DEVICE - Computer, AUTO
OUTPUT - No, CHANNEL DATA - No, ANALOG PLOT - No, SCREEN DUMP - Yes, OVERLAY MODE - No,
FORMAT - Standard, SEND STX/ETX - Yes, END FIELD CHARACTER - 59, END LINE CHARACTER 0
CR+LF, and LEADING ZEROS - Yes.
4)
When the menu check is complete, ensure that the outside of the aperture tube has
been rinsed and immersed in a beaker of clean electrolyte, and that the sample stand door
is closed. The X-axis should be set to linear diameter; the Y-axis should be set to number
differential. Turn the Reset/Count Control clockwise to Reset, applying a vacuum to the
aperture tube system, and, when the light in the sample stand turn on, press the FULL key
on the Multisizer to display the selected range of particle analysis.
5)
Perform a noise check using blank
electrolyte. Acceptable cumulative background counts for both the 200- and 30-micron tubes
are less than 500 counts per 10 seconds.
6)
Shake the fine-fraction portion of the sample in the mason jar vigorously, sonify
the bulk sample for about 2-4 minutes (probes typically work much better than baths; Fig. 10),
and use a stirrer to completely suspend the sample. While
the sample is stirring, transfer a sub-sample, drawn in a sweeping motion from the top,
middle, and bottom of the mason jar, to the clean beaker of filtered electrolyte in the
sample stand using a disposable pipette. Never
allow the tip of the pipette to touch the side or bottom of the mason jar while
sub-sampling because it may break. Set
stirring motor to adequately mix the sample without producing bubbles, close the door to
the sampling stand, turn the Reset/Count Control to reset, and press Full.
7)
Ensure that the concentration index meter reads
5-10%. If the concentration is above 10%, add more electrolyte to dilute. If the concentration is below this, add more
sample to the beaker until 5-10% is reached.
Press the Reset button, wait 5 seconds, and then Start Control buttons to check
that the concentration is less than the maximum for coincidence (<10,000 cts/10 s).
Coincidence is the occurrence of two or more particles in the sensing zone at one time (Fig. 2).
Exceeding coincidence limits will cause data loss in the smaller size classes, thereby
causing the observed grain-size distribution to be coarser (Milligan and Kranck, 1991).
8)
When the concentration is within the correct limits, continue to accumulate data
for about 100 s, then press the Stop button. If
using the program CLTRMS2K (Appendices A and C) to acquire the data, press the
OUTPUT/PRINTER button at the program’s “Please Send Raw Data” prompt. Data
will be sent to the computer and a hardcopy will be generated (Fig. 17).
9) Check the output and, if acceptable,
save the data to disk. To proceed to the next sample remove the beaker from the sample
stand, cover it with cellophane to avoid contamination, and reserve the sample for the
30-micron aperture tube analysis. It is
advisable to perform all of the 200-micron analyses before proceeding to the 30-micron
analyses. Complete only enough 200-micron aperture tube analyses, however, that will allow
adequate time to perform the corresponding 30-micron aperture tube analyses on the same
day.
10) When the 200-micron aperture tube analyses are complete,
the computer program and the Multisizer needs to be reset for the 30-micron aperture tube
analyses. Change the aperture tube, change the Setup menu to the proper settings, place a
clean beaker of electrolyte on the sample stand, and check for acceptable cumulative
background count. Do not use the stirrer
motor during 30-micron aperture tube analyses.
11) Pour sample
saved from 200-micron aperture tube analysis through a clean 20-micron sieve into a clean
electrolyte-rinsed beaker. When the sample has passed through the sieve, pass the sample
back through the sieve into the original beaker, and then through the sieve back into the
new beaker. This re-suspends the sample and ensures that all of the sample has been
scalped by the sieve.
12) Immediately place beaker in the sample stand, close the
sample-stand door, and turn the Reset/Count Control clockwise to reset. Push the Start
button, accumulate data for 100 s, push the Stop button, and push the Print button to send
the data to the computer.
Additional suggestions:
a. Make sure bubbles are
initially cleared from the aperture tube by opening both stopcocks. This will
reduce system noise.
b. If the tube clogs, brush the aperture opening with a
sweeping motion. If the tube is still clogged, clear tube in a distilled-water ultrasonic
bath. If this fails, replace the distilled water with 50 % nitric acid.
c. Always have aperture current off
when not running an analysis or when changing tubes.
d. After the analyses are completed,
the sample stand, Faraday cage, vacuum and electrolyte reservoir flasks, and counter top
should be rinsed in distilled water and dried with paper towels.
e. When the analyses are complete
remove the 30-micron aperture tube, place the 200-micron aperture tube on the sample
stand, and set all switches to the proper settings for the 200-micron analysis.
f. Keep the aperture tubes in a
cleaning solution (e.g. Coulter Clenz) when not in use.
g. With proficiency, an operator can
speed up the analytical procedure by sonifying (Fig. 10)
the next sample while entering pertinent identifiers into the computer for a sample that
is being analyzed by the EMPSA.
Descriptive and Interpretive Measures
Raw grain-size data are typically in the form of weight percentages of sediment in
various size classes. Because many analyses and 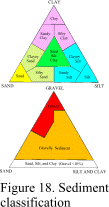 commonly more than one data
set are involved in geological studies, the method by which these data are presented and
compared becomes important when determining how the distributions differ and the magnitude
of these differences (Royse, 1970). Both graphical and statistical methods are available. Of the graphical techniques, one of the more
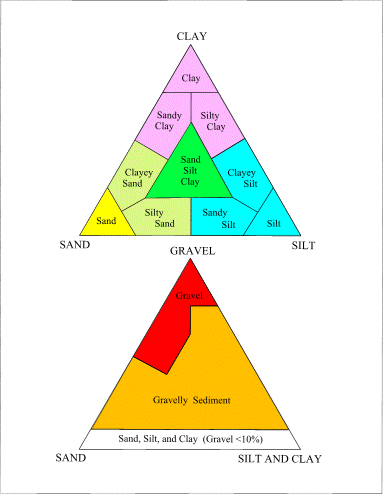
common methods is to plot the basic sand, silt and clay percentages on equilateral
triangular diagrams (Shepard, 1954; Folk, 1956). This means of data presentation is simple
and facilitates rapid classification of sediments and comparison of samples. The USGS
sediment lab at the Woods Hole Field Center uses a modification of Shepard’s (1954)
ternary classification system (Fig. 18).
commonly more than one data
set are involved in geological studies, the method by which these data are presented and
compared becomes important when determining how the distributions differ and the magnitude
of these differences (Royse, 1970). Both graphical and statistical methods are available. Of the graphical techniques, one of the more
common methods is to plot the basic sand, silt and clay percentages on equilateral
triangular diagrams (Shepard, 1954; Folk, 1956). This means of data presentation is simple
and facilitates rapid classification of sediments and comparison of samples. The USGS
sediment lab at the Woods Hole Field Center uses a modification of Shepard’s (1954)
ternary classification system (Fig. 18).
The statistical measures of size distributions used by sedimentologists are most
commonly based on quartile measures (Trask, 1932), phi notation (Inman, 1952; Folk and
Ward, 1957), or the method of moments (Kane and Hubert, 1962; Folk, 1974; Sawyer, 1977). Inclusive graphics statistics, the phi notation
method utilized by the programs provided herein (Folk, 1974), are graphical in that the
data are read directly from a computer-drawn cumulative-frequency curve at five points
(the 5, 16, 50, 84, and 95 percentiles). Verbal equivalents for standard deviation,
skewness, and kurtosis based on the inclusive graphics statistics. The percentages of gravel, sand, silt, and clay,
and the modified frequency percentages for size distributions ranging from 11 ph (or 13
phi using the program CLAYES2K) to -5 phi are also computed. Method of moments statistics,
which involve more complicated arithmetic calculations that account for every grain in the
distribution, have gained popularity with the increasing availability of fast, inexpensive
computers. The method of moments statistics generated with the programs provided herein
include modal classes, modal frequencies, arithmetic mean, median, and standard deviation,
skewness, and kurtosis. However, in
open-ended distributions (truncated distributions or where a lot of material of unkown
size occurs in a pan fraction), the method of moments is probably not justified (Folk,
1974).
Insoluble Residues
The insoluble residue of a sediment is that portion which remains after digestion
in hydrochloric acid (HCL) of a prescribed strength under specific conditions. Because carbonate rocks may contain significant
amounts of chert, anhydrite, and siliciclastic sand, silt, and argillaceous material, the
determination of insoluble residues is useful for comparing sediments from different
localities and for expressing their degree of purity or contamination by detrital and
authigenic constituents (Milner, 1962).
To perform a typical analysis, approximately 15 g of wet sediment are placed in a
pre-weighed 600-ml beaker and dried at 100oC.
The beaker is placed in a desiccator to cool and re-weighed to determine water
content. Cool dilute HCL (10%) is slowly added in stages till all effervescence has
stopped. After effervescence has ceased, the excess acid is carefully decanted. The
insoluble residue is washed at least five times and each washing is decanted. Alternately,
the insoluble residue can be washed into a labeled pre-weighed paper filter and throughly
rinsed. In any case, the insoluble residue is dried at 100oC and is calculated
by weight as a percentage of the original bulk sample.
The difference between 100% and the value obtained is the percent calcium
carbonate. Grain-size analyses may be
performed on the residues, or they may be examined petrographically.
This procedure will remove calcium carbonate. If significant amounts of dolomite
are present, 6N HCL should be used and the suspension must be heated to near boiling to
dissolve the dolomite. The water content need
be determined only if the samples are marine and a salt correction must be applied, or if
appreciable amounts of hygroscopic water are present.
Although commercial grade HCL (muriatic acid) may be used, gypsum formation due to
the presence of sulfate ions is a concern (Krumbein and Pettijohn, 1938). The acid digestion portion of this analysis should
be performed under a fume hood; gloves and safety glasses should be worn.
Comments
The purpose for performing the analyses must be considered when selecting which
method will be used. For example, the Coulter
Counter determines particle volume as opposed to the pipette method which measures
settling rates. Therefore, if a
researcher is studying flow regimes and hydraulic equivalents, the pipette method might
produce more applicable data. Other
settling-velocity analysis methods used for fine-grain sizes are the hydrometer (Buoyocoz,
1928) and decantation methods. However, these
techniques are more difficult and less accurate (Folk, 1974) and thus are generally not
recommended. Numerous journal articles have
compared the various techniques used for size analyses of fine-grained suspended
sediments. All operators contemplating the
use of any of these methods are strongly encouraged to familiarize themselves with this
literature. For example, Shideler (1976) and
Behrens (1978) compared the Coulter Counter with pipette techniques. Hydrophotometers have
been compared with the pipette method (Jordan and others, 1971; Singer and
others, 1988) and with the Coulter
Counter (Swift and others, 1972). The above
fine-fraction considerations also apply to the coarse fraction. The coarse fraction is usually determined by
settling-tube analysis. However, if this
fraction weighs less than 10 g or contains greater than 2-5% foraminifera which will not
settle properly in a sedimentation column, the operator must utilize sieves, which will
measure nominal diameter. These and other
particle-size methods and considerations are discussed in Barth (1984) and Syvitski
(1991).
Aggregates of clay-sized particles, which are difficult to break up, commonly form
when samples are dried. Because these aggregates or “bricks” cause the size
distribution to appear slightly (about 2-4%) coarser, care should be exercised to sonify
samples with appreciable clay-sized material for at least 4 minutes prior to EMPSA
analysis to minimize this effect. Other
techniques to determine the weight percentages of the coarse and fine fractions that do
not involve drying the fine fraction include pipette analyses and splitting the sample. In
the latter technique where the sample is split, half is dried to determine the percentages
of the coarse and fine fractions and the fine fraction from the other undried half is
analyzed by EMPSA. Unfortunately, getting
representative splits is difficult because of intra-sample heterogeneity and the splitting
process can commonly introduce an error much greater than the original 2-4 percent. For
those interested in a determination of the entire clay fraction with the greatest
accuracy, pipette analyses or the use of the computer program CLAYES2K (Appendices B and
C) are strongly recommended.
Quality Assurance
Extensive textural analyses performed on standards have shown that the above
methods, with the possible exception of the hydrometer, will produce results with an
accuracy of better than plus or minus 10% (electro-resistance multichannel particle size
analyzer: about 3%; sieves: about 5%; pipette and sand-fraction settling tube: about 5%). However, the optimum precision for the above
analyses is realized only if the operator is conscientious in attention to detail and
consistently follows established procedure. To
monitor precision, the operator should run replicates on at least every tenth sample.
The representativeness of any textural data set depends on
the methods used to obtain the data. These
methods must be chosen in accordance with the original purpose of the study. If the importance of knowing the actual size
distribution outweighs the hydraulic equivalence, the sieve and the particle-counter
analyses should be performed rather than the settling-tube and pipette analyses.
The comparability problems between sets of data generated by different devices are
not as great as one might expect. For
example, the data produced by sieve and settling tube analyses would be remarkably similar
for a given sample because a settling tube is usually calibrated using natural sediments
sieved to known fractions. On the other hand,
pipette and hydrometer analyses will usually produce data indicating a given sample is
slightly finer than the data produced on an EMPSA. This result occurs because
fine-fraction particles are generally plate shaped and do not settle as fast as the quartz
spheres upon which Stoke's Law, and therefore the pipette and hydrometer settling
analyses, is based. And again, an EMPSA can not typically be calibrated to analyze the
very fine clay (less than 0.6 microns) and colloidal-clay portions of the size
distribution.
VIDEO DEMONSTRATIONS OF LABORATORY
PROCEDURES
Six videos with voice commentary were produced as a guide for laboratory
technicians and students in the earth-science and oceanographic communities who would like
to use the above described methods. They are
not intended to be detailed presentations of the procedures, but to serve only as
supplements to help familiarize users with the basic principles. Users are strongly encouraged to consult the
original references cited above for more detailed analytical descriptions.
Operational Procedures
The free multi-media software, RealPlayer,
must be installed on the user’s computer with a web browser before the videos, which
are stored as compressed streaming files, can be viewed.
Once installed, if using Internet Explorer, the user can launch the demonstration
videos below by clicking on the respective links. If the user's
browser does not connect properly to the links below, the
user should get out of the browser, go directly to the videos directory of chapter1 and open the
respective .rm files with RealPlayer.
RealPlayer
Video Files
LITHOLOGIC SYMBOLS
 The basic lithologic symbols shown in figure 19
are provided as guidelines. Symbols similar
to these are generally acceptable for use as patterns both on sediment distribution maps
and in lithologic columnar sections, such as on core description forms. Although these are the most commonly used symbols
for each of the respective lithologies, the patterns must still be explained separately in
a key. As with most graphics, users should
also be mindful of the eventual publication scale when choosing line weights.
The basic lithologic symbols shown in figure 19
are provided as guidelines. Symbols similar
to these are generally acceptable for use as patterns both on sediment distribution maps
and in lithologic columnar sections, such as on core description forms. Although these are the most commonly used symbols
for each of the respective lithologies, the patterns must still be explained separately in
a key. As with most graphics, users should
also be mindful of the eventual publication scale when choosing line weights.
SOFTWARE
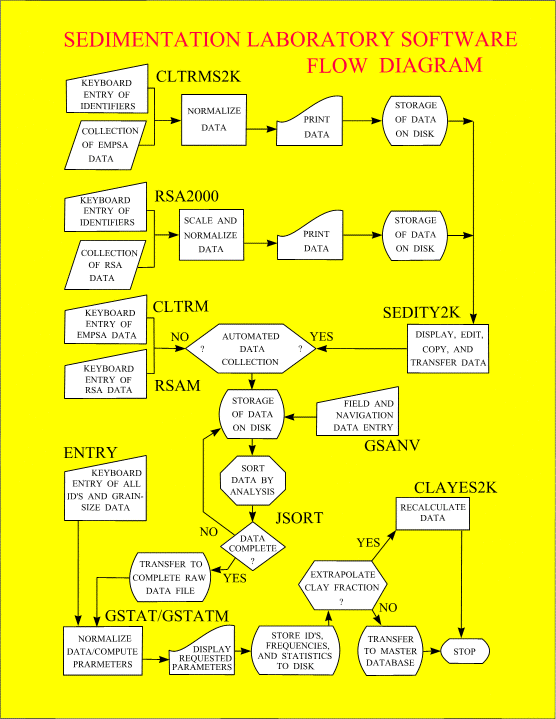
Figure
20 outlines the software sequence of operation in a generalized flow diagram for
those programs used on the computers in the sedimentation laboratory at the Woods Hole
Field Center. The data-acquisition programs RSA2000, CLTRMS2K, and SEDITY2K, and the
data-processing program CLAYES2K, run in DOS 3.0 or later and in DOS under Windows
3.1,/95/98. The data-acquisition programs GSANV, RSAM, CLTRM, and ENTRY, and the
data-processing programs JSORT, GSTAT, and GSTATM, run under Windows 95/98 in the
“Born-Again-Shell” (bash). This shell, which is part of the GNU operating system
(Hagerty and others, 1998) distributed by the Free Software Foundation, creates a
Unix-like environment under Microsoft Windows 95/98.
 Raw data records are created on IBM-compatible computers interfaced with an RSA and
EMPSA by using the programs RSA2000 and CLTRMS2K, respectively (Appendices A and C). The user is prompted for all the necessary
identifiers, and, upon completion of a satisfactory analysis, the data and identifiers can
be written to both an output file and a printer. Three raw data records are generated for
each sample: an RSA record, a 200-micron aperture tube EMPSA record, and a 30-micron
aperture tube EMPSA record. These records each contain a lab number, equipment
type, sample identification, project identification, requestor, operator, and analysis
date. The RSA data records include sample weight, coarse weight, sand weight, and the
relative percentages of the-5 to -1 phi gravel and 0 to 4 phi sand fractions. The EMPSA data records include aperture diameter
and tabulated micrometer diameters and the corresponding relative-frequency percentages
from the size-fraction channels collected by the Coulter Counter Multisizer IIe. Although
the Multisizer IIe generates 256 channels of data, this accuracy is unnecessary when
generating whole-phi grain-size distributions. The program CLTRMS2K combines and reduces
the data into a more manageable 16-channel format that is equivalent to the data
originally produced by the Coulter Counter Model TAII.
Raw data records are created on IBM-compatible computers interfaced with an RSA and
EMPSA by using the programs RSA2000 and CLTRMS2K, respectively (Appendices A and C). The user is prompted for all the necessary
identifiers, and, upon completion of a satisfactory analysis, the data and identifiers can
be written to both an output file and a printer. Three raw data records are generated for
each sample: an RSA record, a 200-micron aperture tube EMPSA record, and a 30-micron
aperture tube EMPSA record. These records each contain a lab number, equipment
type, sample identification, project identification, requestor, operator, and analysis
date. The RSA data records include sample weight, coarse weight, sand weight, and the
relative percentages of the-5 to -1 phi gravel and 0 to 4 phi sand fractions. The EMPSA data records include aperture diameter
and tabulated micrometer diameters and the corresponding relative-frequency percentages
from the size-fraction channels collected by the Coulter Counter Multisizer IIe. Although
the Multisizer IIe generates 256 channels of data, this accuracy is unnecessary when
generating whole-phi grain-size distributions. The program CLTRMS2K combines and reduces
the data into a more manageable 16-channel format that is equivalent to the data
originally produced by the Coulter Counter Model TAII.
The raw RSA and EMPSA data are archived into master files by using the program
SEDITY2K (Appendices A and C). This program also
contains utilities to inspect, edit, and print hard copies of the data generated by the
RSA2000 and CLTRMS2K programs.
Occasionally, distribution and statistics must be generated for samples which were
not analyzed or only partially analyzed with the RSA2000 and CLTRMS2K programs. For example, many fine-grained samples do not
contain enough sand (< 10 g) to perform settling-tube analyses, and the entire coarse
fraction (>0.062 mm) must be determined by sieving or approximated by visual estimates.
When this occurs, a raw data master file may be created or updated by keying the raw
sediment data directly into a file using the programs RSAM and CLTRM (Appendices A and C). These programs prompt the user for all necessary
identifiers and data. The data can then be
processed as output from the programs RSA2000 or CLTRMS2K.
The field and navigation parameters are entered by using the program GSANV
(Appendix A and C). These parameters and their coding are described in the Request For
Analysis forms which have been completed by all personnel who submit samples for
particle-size analysis. The field and
navigation parameters include lab number, latitude, longitude, area, sampling device,
water depth, depth in section to the top of the sample, and depth in section to the bottom
of the sample.
The data-processing program JSORT (Appendices B and C) is used to sort the
multi-line records according to lab numbers and to output the records that are complete
(all RSA and EMPSA data, and field and navigation parameters) to an output file for
further processing. The program GSTAT
(Appendices B and C) is used to retrieve data from the complete, sorted, raw data files
created by JSORT and to compute the modified frequency percentages, method of moments
statistics, textural nomenclature and classification (Wentworth, 1929; Shepard, 1954; Figs. 9,
18),
and percentages of gravel, sand, silt, and clay. The
modified frequency percentages are given for size distributions up to and including 11 phi
to -5 phi. The method of moments statistics
includes arithmetic mean, median, standard deviation, skewness, kurtosis, modal classes,
and modal frequencies. If requested by the user, a hardcopy of this output (Fig. 21),
which also includes inclusive graphics statistics and verbal equivalents for standard
deviation, skewness, and kurtosis (Folk, 1974), can be produced. The frequency percentages
for the corresponding phi classes are computed by the subroutines MPVC, SUMRY, and WTFP
(Appendix C). The cumulative frequency-percent curve used in computing the inclusive
graphics statistics is approximated by using the International Mathematical and
Statistical Library Inc. (IMSL) routines IQHSCU and ICSEVU (Appendix C).
The programs ENTRY and GSTATM (Appendices B and C) allow the
user to generate statistics for pre-existent grain-size data produced outside the software
system described above. The program ENTRY permits input of sediment data as relative
frequency percentages at whole-phi intervals; the program GSTATM performs the functions of
the program GSTAT on these data. To correct
the errors introduced by the assumption that each value within a phi class is centered at
the midpoint of that class, Shepard's Correction (Kenny and Keeping, 1951) has been
applied to the second and fourth moments about the mean in the statistics generated by the
programs GSTAT and GSTATM.
When creation of a database file is specified in either GSTAT or GSTATM, the
cumulative frequency percentages, phi classes, method of moments statistics, and the
appropriate identifiers are written to a “pre-database” file in a
comma-delimited free-field format. Once the data are in a database, multi-variate analyses
such as factor analysis or cluster analysis may be applied to retrieved data to help
interpret complicated sedimentological phenomena.
Because an EMPSA can detect only those particles for which it is calibrated, the
tail of the fine fraction produced by this instrumentation (below about 0.6-0.7 microns)
is commonly truncated. The program CLAYES2K
(Poppe and Eliason, 1999; Appendices B and C) allows the user to extrapolate the grain-size distribution
contained in the “pre-database” file generated by the program GSTAT to the
colloidal-clay boundary. The user may select
solutions based on linear or exponential extrapolations, or the mean of both.
Figure
22 presents a stylized plot showing that portion of the grain-size distribution
typically truncated by EMPSAs. Also shown in this figure are examples of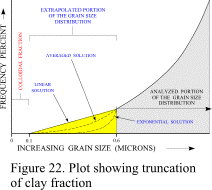 linear, exponential, and
averaged extrapolations of the clay fraction to 0.1 microns, and the clay-colloidal clay
boundary. Errors inherent in the linear and
exponential extrapolations have been exaggerated within this figure to more clearly
demonstrate their effect on the grain-size distribution.
The linear extrapolation tends to slightly overestimate the amount of clay present
in a typical distribution and may be used by operators to account for some of the material
within the colloidal fraction. The
exponential extrapolation tends to slightly underestimate the amount of clay present in a
typical distribution and may be used by operators who want data that represents the
minimal amount of clay present. Although an
operator may select linear or exponential extrapolation, the mean of both extrapolations
usually provides the most accurate estimate and is, therefore, the recommended solution
for most applications.
linear, exponential, and
averaged extrapolations of the clay fraction to 0.1 microns, and the clay-colloidal clay
boundary. Errors inherent in the linear and
exponential extrapolations have been exaggerated within this figure to more clearly
demonstrate their effect on the grain-size distribution.
The linear extrapolation tends to slightly overestimate the amount of clay present
in a typical distribution and may be used by operators to account for some of the material
within the colloidal fraction. The
exponential extrapolation tends to slightly underestimate the amount of clay present in a
typical distribution and may be used by operators who want data that represents the
minimal amount of clay present. Although an
operator may select linear or exponential extrapolation, the mean of both extrapolations
usually provides the most accurate estimate and is, therefore, the recommended solution
for most applications.
RSA2000, CLTRMS2K, SEDITY2K, and CLAYES2K were written and compiled in Microsoft
QuickBASIC version 4.5; RSAM, CLTRM, GSANV, JSORT, GSTAT, ENTRY, and GSTATM were
originally written in RATFOR (Poppe and others, 1985), but have been rewritten in
“C” and compiled with the DJGPP Development System v. 2.01 (Walnut Creek CDROM).
ACKNOWLEDGMENTS
This report is preliminary and has not been reviewed for conformity with U.S.
Geological Survey editorial standards (or with the North American Stratigraphic Code). Any
use of trade, product, or firm names is for descriptive purposes only and does not imply
endorsement by the U.S. Government. The software presented herein is provided as a
service; no warranty is given or implied. Images
on the title page and table of contents are clipart from Corel XARA (v. 1.5). We thank A. Robinson, J. Commeau, and D. Walsh,
the sediment lab analysts who assisted during preparation of this report.
REFERENCES CITED
Barth, N.G.,
1984, Modern methods of particle size analysis, John Wiley and Sons, 309 p.
Behrens, E.W., 1978, Further
comparisons of grain size distributions determined by electronic particle counting and
pipette techniques: Journal Sedimentary Petrology, v. 48, no. 1, p. 121.3-1218.
Benson, D.J., 1981, Textural analyses
with Texas Instruments 59 programmable calculator:
Journal Sedimentary Petrology, v. 51, no. 2, p. 61-62.
Berg, R.H., 1958, Electronic size
analysis of sub-sieve particles by flowing through a small liquid resistor: ASTM Special
Technical Publication 234, p. 245-258.
Blackwood, D.B. and Parolski, K.F.,
2000, "SEABOSS": an elegantly simple image and sampling system: Proceedings of
the Sixth International Conference on Remote Sensing for Marine and Coastal Environments,
Veridan ERIM International, v. 1, p. I-99-I-106.
Blatt, Harvey, Middleton, Gerard, and
Murray, Raymond, 1972, Origin of Sedimentary Rocks: Englewood Cliffs, New Jersey,
Prentice-Hall, 634 p.
Bothner, M.H., Gill, P.W., Boothman,
W.S., Taylor, B.B., and Karl, H.A., 1997, Chemical and textural characteristics of
sediments at the EPA reference site for dredged material on the continental slope SW of
the Farallon Islands: U.S. Geological Survey Open-File Report 97-87, 50 p.
Buoyocoz,
G.J., 1928, The hydrometer method for studying soils. Soil Science, v. 25, p. 365-369.
Coulter, W.H., 1957, High speed
automatic blood cell counter and cell size analyzer: proceedings of the National
Electronics Conference, p. 1034-1042.
Coulter Electronics, Inc., 1988, Fine
particle application notes: Instruction manual, Hialeah, Florida 72 p.
Coulter Electronics, Inc., 1989,
Coulter Multisizer AccuComp color software: Reference Manual, Hialeah, Florida, 188 p.
Emery, K.O. and Schlee, J.S., 1963, The
Atlantic Continental Shelf and Slope, A Program for Study: U.S. Geological Survey Circular
481, 11 p.
Emmitt, W.W., 1980, A field calibration
of the sediment-trapping characteristics of the Helley-Smith Bedload Sampler: U.S.
Geological Survey Professional Paper 1139, 44 p.
Folk, R.L.,
1956, A review of grain-size parameters: Sedimentology,
v. 6, p. 77-93.
Folk, R.L., and Ward, W.C., 1957,
Brazos River bar - a study in the significance of grain size parameters: Journal
Sedimentary petrology, v. 27, p. 3-26.
Folk, R.L., 1974, The petrology of
sedimentary rocks: Austin, Tex., Hemphill Publishing Co., 182 p.
Hagerty, Dan, Weisshaus, Melissa, and
Zaretskii, Eli, 1998, GNU software for Ms-Windows and Ms-DOS: Boston, MA, Free Software
Foundation, 108 p.
Honjo, S., Spencer, D., and Gardner,
W., 1992, A sediment intercomparison experiment in the Panama Basin: Deep-Sea Research, v. 39,
p. 333-358.
Inman, D.L., 1952, Measures for
describing size of sediments: Journal Sedimentary Petrology, v. 19, p. 51-70.
Jackson, M.L., 1956, Soil chemical
analysis: advanced course: Published by the author,. Madison, Wis., 895 p.
Jones, S.B., and Simpkin, P., 1970, A
computer program for the calculation of hydrometer
size analyses: Marine Geology, v. 9, p. M23-M29.
Jordan, C.F., Jr., Fryer, G.E., and
Hemmen, E.H., 1971, Size analysis of silt and clay by hydrophotometer- Journal Sedimentary
Petrology, v. 41, no. 2, p. 489-4 96.
Kane, W.T., and Hubert, J.F., 1962,
FORTRAN program for the calculation of grain-size textural parameters on the IBM 1620 computer: Sedimentology, no. 2, p.
87-90.
Kranck, K. and Milligan, T.G., 1979,
The use of the Coulter Counter in studies of particle-size distributions in aquatic
environments: Bedford Institute Report Series B1-R, v. 79, p. 7.
Kennedy, S.K., Meloy, T.P., and Durney,
T.E., 1985, Sieve data - size and shape information: Journal Sedimentary Petrology, v. 55,
p. 356-360.
Kenny,
J.F., and Keeping, E.S., 1954. Mathematics of statistics, Part 1: Princeton,
N.J., D. Van Nostrand Company, Inc., 348 p.
Krumbein, W.C., and Pettijohn, F.J.,
1938, Manual of Sedimentary Petrology, New York, Appleton, Century, and Crofts, 549 p.
Lay, E.P.,
1969, Core sampling techniques, Oceans Magazine, v.
1, no. 3, p. 27-29.
Lee, H.J., and Clausner, J.E., 1979,
Sea-floor sampling and geotechnical parameter determination - handbook: Technical Report
R873, Civil Engineering Laboratory, Naval Construction Battalion Center, Port Hueneme, CA,
127 p.
McCave, I.N., and Jarvis, J., 1973, Use
of the Model T Coulter Counter in size analysis of fine to coarse sand: Sedimentology, v.
20, p. 305-315.
McCave, I.N., and Syvitski, J.P.M.,
1991, Principles and methods of particle size analysis, In J.P.M. Syvitski (ed.),
Principles, Methods, and Applications of Particle Size Analysis, New York, Cambridge
University Press, p. 3-21.
McLane
Research Laboratories, 2000, Mark 78G-21 Sediment Trap: http://www.mclanelabs.com/
McManus,
D.A., 1963, Sieve calibration: Journal Sedimentary Petrology, v. 33, p. 953-954.
McManus, D.A., 1965, A study of maximum
load for small diameter sieves,: Journal Sedimentary Petrology, v. 35, p. 792-796.
Milligan, T.G., and Kranck, Kate, 1991,
Electro-resistance particle size analyzers, In J.P.M. Syvitski (ed.), Principles, Methods,
and Applications of Particle Size Analysis, New York, Cambridge University Press, p.
109-118.
Milner,
H.B., 1962, Sedimentary Petrography: New York, Macmillan Company, 643 p.
Mizutani, S., 1963, A theoretical and
experimental consideration on the accuracy of sieving analysis: Journal Earth Science, v.
11, 27 p.
Muerdter, D.R., Dauphin, J.P., and
Steele, G., 1981, An interactive computerized system for grain size analysis of silt using
electro-resistance: Journal of Sedimentary Petrology, v. 51, p. 647-650.
North Carolina State University, 1999,
Shipek grab sampler: Web Site, http://www.ncsu.edu/coast/research/shipek/shipek5.jpg
PetterssonO., 1928, A new appartus for
taking bottom samples: Svensk Hydrological Biological Komm Skrift, v. 6, p. 1-7.
Phleger, F.B., 1951, Ecology of
foraminifera, northwest Gulf of Mexico: Geological Society America Memoir 46, Part 1, 88
p.
Poppe, L.J., Eliason, A.H., and
Fredericks, J.J., 1985, APSAS: an automated particle-size analysis system: U.S. Geological
Survey Circular 963, 77 p.
Poppe, L.J., and Elisaon, A.H., 1999,
An interactive computer program to extrapolate the clay fraction distributions of
truncated grain-size data: U.S. Geological Survey Open-File Report 99-27, 44 p.
PVL
Technologies Inc., 2000, VC-3.5 vibracore: http://www.pvltech.com
Reineck, H.E., and Singh, I.B., 1980,
Depositional sedimentary environments with references to terrigenous clastics: 2d ed.,
Berlin and New York, Springer-Verlag, 549 p.
Rickly Hydrological Company, 2000, US
BLM-84 --USGS-designed bedload samplers: http://www.rickly.com/
Rigler, J.K., Collins, M.B., and
Williams, S.J., 1981, A high-precision digital-recording sedimentation tower for sands:
Journal of Sedimentary Petrology, v. 51, p. 642-644.
Rosfelder, A.M., and Marshall, N.F.,
1967, Obtaining large, undisturbed and oriented samples in deep water, In A.F. Richards
(ed.) Marine Geotechnique, Proceedings of 1966 International Conference in Marine
Geotechnique, University of Illinois Press, p. 243-262.
Royse, C.F., 1970, An introduction to
sediment analysis: Tempe, Arizona, Arizona State University, 180 p.
Sahu, B.K.,
1965, Theory of sieving: Journal Sedimentary Petrology, v. 35, p. 750-753.
Sawyer, M.B., 1977, Computer program
for the calculation of grain-size statistics by the method of moments: U.S. Geological
Survey Open-File Report 77-580, 15 p.
Schlee, J., 1966, A modified Woods Hole
Rapid Sediment Analyzer: Journal Sedimentary Petrology, v. 30, p. 403-413.
Schlee, J., and Webster, J., 1967, A
computer program for grain-size data: Sedimentology, v. 8, p. 45-54.
Schlee, J., 1973, Atlantic continental
shelf and slope of the United States -- sediment texture of the northeastern part: U.S.
Geological Survey Professional Paper 529-L, 64 p.
Sea
Surveyor Inc., 2000, Alpine vibracorer: http://www.seasurveyor.com
Sheldon, R.W., and Parsons, T.R., 1967,
A practical manual on the use of the Coulter Counter in marine research: Toronto, Coulter
Electronics, 66 p.
Shepard, F.P., 1954, Nomenclature based
on sand-silt-clay ratios: Journal Sedimentary Petrology, v. 24, p. 151-158.
Shepard,
F.P., 1963, Submarine Geology: New York, Harper and Row, 557 p.
Shideler, G.L., 1976, A comparison of
electronic particle counting and pipette techniques in routine mud analysis: Journal
Sedimentary Petrology, v. 46, no. 4, p. 1017-1025.
Singer, J.K., Anderson, J.B.,
Ledbetter, M.T., McCave, I.N., Jones, K.P.N., and Wright, R., 1988, An assessment of
analytical techniques for size analysis of fine-grained sediments: Journal Sedimentary
Petrology, v. 58, p. 534-543.
Smith, W., and McIntyre, A.D., 1954, A
spring-loaded bottom sampler: Journal Marine Biological Association, v. 33, p. 257-264.
Swift, D.J.P., Schubel, J.R., and
Sheldon, R.W., 1972, Size analysis of fine-grained suspended Sediments--a review: Journal
Sedimentary Petrology, v. 42, no. 1, p. 122-134.
Syvitski, J.P.M., Asprey, K.W., and
Clattenburg, D.A., 1991, Principles, design, and calibration of settling tubes: In J.P.M.
Syvitski (ed.), Principles, Methods, and Applications of Particle Size Analysis, New York,
Cambridge University Press, p. 3-21.
Trask, P.D., 1932, Origin and
environment of source sediments of petroleum: Houston, TX, Gulf Publication Company, 323
p.
Twenhofel, W.H., and Tyler, S.A., 1941,
Methods of study of sediments: McGraw Hill, New York, 183 p.
Wentworth, C.K., 1929, Method of
computing mechanical composition of sediments: Geological Society of America Bulletin, v.
40, p. 771-790.
Zeigler, J.M., Whitney, G.G., Jr., and
Hayes, C.R., 1960, Woods Hole Rapid Sediment Analyzer: Journal of Sedimentary Petrology, v. 30,
p. 490-495.
Zeigler, J.M., Hayes, C.R., and Webb,
D.C., 1964, Direct readout of sediment analyses by settling tube for computer processing:
Science, v. 145, p. 51.
FIGURE CAPTIONS
Figure 1. Schematic diagram showing
the basic design of a rapid sediment analyzer (RSA;
Schlee, 1966), a settling tube.
Figure 2. Basic design of an electro-resistance multichannel
particle size analyzer (EMPSA).
Figure 3. Generalized flow diagram outlining the laboratory
techniques and the computer software used in the sedimentation laboratory at the Woods
Hole Field Center.
Figure 4. A form used at the
USGS Woods Hole Field Center to request grain-size analyses. Form
supplies sample identifiers and defines the purpose of the project and the laboratory
procedures to be employed.
Figure 5. Form used to record sample identifiers and assign
the corresponding lab numbers. Information supplied includes: submitter, cruise id,
project id, latitude, longitude, water depth in meters, sampling device area, top depth
within the sediment column in centimeters, and bottom depth within the sediment column in
centimeters. Information from this form is entered into a computer using the programs
GSANV or ENTRY.
Figure 6. Form used to record and calculate analytical data
during grain-size and carbonate analyses. Grain size data from this form are entered into
a computer using the programs RSAM and RSA2000.
Figure 7. Photograph showing a typical convection oven used
to dry samples and a desiccator used to store samples prior to weighing.
Figure 8. Photograph showing an analyst in the process of
wet sieving a sample.
Figure 9. Correlation chart showing the relationships
between phi sizes, millimeter diameters, size classifications (Wentworth, 1929), and ASTM
and Tyler sieve sizes. Chart also shows the corresponding intermediate diameters, grains
per milligram, settling velocities, and threshold velocities for traction.
Figure 10. Photograph showing a typical distillation
system used to produce distilled water and a sonic probe used to disaggregate particles prior to
EMPSA and pipette analysis.
Figure 11. Basic filtration system used to remove
submicron-sized particles from the electrolyte/dispersant used during EMPSA and pipette
analyses.
Figure 12. Photograph of a rapid sediment analyzer,
a settling tube. This
instrument (Schlee, 1966) uses a pressure transducer to monitor the settling of sediment
with time. An amplifier demodulator on the shelf next to the settling tube relays
electrical information to and analog-to-digital converter in the computer.
Figure 13. Photograph of a bank of sieves mounted in a sieve
shaker. The shaker sits in a sound-proof cabinet.
Figure 14. Hard copy of a coarse-fraction raw data record
produced by the computer program RSA2000. Plot is stylized.
Figure 15. Photograph of a Coulter Counter Multisizer IIe and
associated computer hardware.
Figure 16. Form used to record and calculate sample
identifiers and data generated during a pipette analysis. Data from pipette analyses can
be entered into a computer using the program ENTRY.
Figure 17. Hard copy of a fine-fraction raw data record
produced by the computer program CLTRMS2K.
Figure 18. Sediment classification scheme modified from
Shepard (1954) used by the programs GSTAT and GSTATM.
Figure 19. Basic lithologic symbols commonly used on sediment
distribution maps and in lithologic columnar sections.
Figure 20. Generalized flow diagram showing the available
grain-size analysis software and its sequence of operation.
Figure 21. Hard copy of
a data record produced by the computer programs GSTAT and GSTATM. Hard copy shows
sample identifiers, size distribution, method of moments and inclusive graphics
statistics, and verbal equivalents.
Figure 22. Stylized plot showing that portion of the clay
fraction typically truncated by electro-resistance particle size analyzers. Also shown are examples of linear, exponential,
and average of the linear and exponential extrapolations to 0.1 microns, the
clay-colloidal boundary by the program CLAYES2K. Errors
inherent in the linear and exponential solutions have been exaggerated to show their
effect.
Figure 23. Raw data records produced by the computer program
GSANV.
Figure 24. Raw coarse-fraction data records from the Rapid
Sediment Analyzer produced by the computer program RSA2000 and output into a file by the
program SEDITY2K. The first line, which is
the master file name assigned by the operator with the program SEDITY2K, must be deleted
before further processing.
Figure 25. Raw fine-fraction data records from the Coulter
Counter (200- and 30-micron analyses) produced by the computer program CLTRMS2K and output
into a file by the program SEDITY2K. The
first line, which is the master file name assigned by the operator with the program
SEDITY2K, must be deleted before further processing.
Figure 26. Data file produced by the computer programs GSTAT
and GSTATM and used as input for the computer program CLAYES2K. Fields are delimited by
commas; records are delimited by dollar signs. A header file has been inserted as the
first record to show the field attributes and their order.
Figure 27. Hard copy of a data record produced by the
computer program CLAYES2K. The sample identifiers and the original and revised data are
shown.
Figure 28. Data file produced by the computer program
CLAYES2K. Fields are delimited by commas; records are delimited by dollar signs. A header file has been inserted on the first line
to show the field attributes.
APPENDICES
APPENDIX A. SOFTWARE DOCUMENTATION AND CODE FOR
DATA-ACQUISITION SOFTWARE
1.) GSANV
Name: gsanv - to facilitate keyboard entry of navigation
and descriptive information associated with raw sediment data processed during grain-size
analysis.
Synopsis
gsanv [-c]
file_name
Description: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98
in the Born-Again-Shell (Bash). The program prompts the user for each of the parameters to
be entered into the output file (Fig. 23). All prompts are self-explanatory.
When the
“-c” option is specified on the run-line, the latitude and longitude are
expected as “deg min Q” where Q is N, S, E, or W. These values are then
converted into decimal degrees; S and W are converted to negative values. Otherwise, the
navigation is expected as plus/minus decimal degrees.
A
“Control C” will cause immediate termination of the program. All data entered
during the current run will be lost.
A carriage
return in response to the sampling device, area, depth, top depth, or bottom depth prompts
will cause the default value to be used as the response. The default value, which after
the first record is the previous response for a particular attribute, is displayed in the
parentheses of the prompt. A dash and carriage return in response to the prompt will enter
a blank as the response. The depth is expected in meters; the top and bottom depths are
expected in centimeters.
FILES
gsanv.c,
sedlab.h, iolab.c
SEE ALSO
gstat
DIAGNOSTICS/BUGS
No imbedded
commas or spaces are allowed in the responses
AUTHOR/MAINTENANCE
Janet Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
2.) RSAM
NAME: rsam - to enter sand-fraction (sieve and rapid
sediment analyzer; Figs 1, 9, and 12) and gravel fraction data via the keyboard
SYNOPSIS
rsam
afile_name
DESCRIPTION: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98 in the Born-Again-Shell (Bash). For each
file named, the user is prompted for a set of project identifiers. These will remain
constant for each file. If the file named
exists, data are appended to the file. Otherwise,
the file will be created. All prompts are self-explanatory.
Data are
written to the file when all sand and gravel data have been entered. Data are entered as
two separate groups: sand being phi 4 to phi
0, gravel being phi -1 to phi -5. Each phi group must sum to 100 +- .1% . Otherwise, the
user is prompted to re-enter the phi group. When the sample weight is equal to the coarse
weight, the user is not prompted to enter
gravel data.
The program
may be aborted at any time by hitting the “Control C” key.
FILES
sedlab.h
SEE ALSO
rsam.c
getcoars.c getids.c rsetup.c rprint.c /utils/iolib.c
DIAGNOSTICS-BUGS
Each
response will have a maximum field length as specified in sedlab.h . If the user response
is too long, the program will specify the maximum number of characters allowed for the
current response.
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
3) CLTRM
NAME: cltrm - to enter 200 and/or 30 micron diameter
tube elecrto-resistance multichannel particle-size analyzer (EMPSA, e.g. Coulter Counter; Figs. 2,
15)
analyses via the keyboard
SYNOPSIS
cltrm afile_name
DESCRIPTION: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98 in the Born-Again-Shell (Bash). For each
file named, the user is prompted for a set of project identifiers. These will remain
constant for each file. If the file named
exists, data are appended to the file. Otherwise,
the file will be created.
Data are
written to the file each time the user responds 'y' (in lower case) to the prompt
"Are data ok?". A “period and carriage return” will terminate the data correction mode. The
program may be aborted at any time by hitting “Control C”
FILES
sedlab.h
SEE ALSO
cltrm.c
getsam.c getids.c getopt.c csetup.c mprint./utils/iolib.c
DIAGNOSTICS-BUGS
Each
response will have a maximum field length as specified in sedlab.h . If the user response
is too long, the program will specify the maximum number of characters allowed for the
current response.
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
4.) RSA2000
NAME:
RSA2000
TYPE: Main
program
PURPOSE: To
create raw rapid sediment analyzer (RSA; Figs. 1, 12)
data records
OPERATING
SYSTEM: DOS version 3.0 or later, or DOS under Windows 3.1/95/98
SOURCE
LANGUAGE: Microsoft QuickBASIC
SOURCE
CODE: RSA2000.BAS
COMPILED
SOFTWARE: RSA2000.EXE
SEE ALSO:
This program requires and/or generates the following associated data files. The files
contain only ASCII (viewable) data and reside in the same directories (folders) as the
associated executable.
ADAC.DAT -- Initialization file required to set up ADAC a/d board. An
example file is included using IRQ 4. The IRQ must be reserved for the card. Please see
ADAC documentation for more information.
RAWINDEX.DAT -- Required to run program. May be set initially to just
contain ASCII “0” (character zero).
RawDat*.DAT -- *= 1,2,3 Intermediate data generated by the program during
successive runs.
RSA.DAT -- Reduced data generated by the program. No initial file is needed but the
file contains data from all saved runs. It is maintained by the program SEDITY2K.EXE.
RSA.NDX -- Index file to RSA.DAT. An initial file will be created upon first run.
MIXED_AD.LIB -- Library file needed in
the development environment (QuickBASIC) to compile the program
MIXED_AD.QLB -- Quick library file needed in the development environment to compile
the program.
RSA2000.MAK -- A MAK file that uses WINDOWS.BAS, BITS.BAS, BIOSCALL.BAS,
MOUSSUBS.BAS, and KEYS.BAS. These files are included in Microsoft QuickBASIC
Programmer’s Toolbox and are also needed in the development environment to compile
the program.
INPUT: At
the beginning of each run, the operator will be prompted for the plotter scale, operator,
requestor, cruise id, project id, sample id, lab number, sample weight, coarse weight,
sand weight, and relative percentages of the phi classes from the gravel fraction.
OUTPUT: A
raw data record stored to disk and a hard copy (Fig. 14)
USAGE: To use the program from DOS, change to the working
directory and type: RSA2000
To use the
program from Windows 95/98, access it from the file manager or the Run command
The user is
prompted for all necessary identifiers and data. For each run enter the plotter scale
(program defaults to full scale). For each analysis enter:
a) Operator
b) Requestor
c)Cruise id
d) Project id
e) Sample id
f) Lab Number
g) Sample weight
h) Coarse weight
i) Sand weight
j) Relative percentages of the phi classes from the gravel fraction
The sample is introduced into the
settling tube when the “Waiting For Sample Introduction” prompt is given.
A copy of the identifiers, the data,
and the cumulative frequency plot of the pressure change versus time are generated on the
printer (Fig. 14).
The operator may then save , reprint,
smooth, or, if the analysis was no good, purge the data. A default saves the data. Upon
responding to a choice, the program is recycled.
A default (carriage return) to any of
the prompted identifiers other than sample id or Lab Number will enter the identifier from
the previous analysis.
RESTRICTIONS: Operator, requestor, cruise id, and project id may
be up to 19 characters and have no imbedded spaces or commas. Speed requirements
necessitate the BASIC source code be compiled into machine language.
AUTHOR/MAINTENANCE: Eliason Data Services, Mashpee, MA/L. Poppe,
USGS, Woods Hole, MA
5.) CLTRMS2K
NAME:
CLTRMS2K
TYPE: Main
program
PURPOSE: To
create raw EMPSA (Coulter Counter; Figs. 2, 15)
data records
OPERATING
SYSTEM: DOS version 3.0 or later, or DOS under Windows 3.1/95/98
SOURCE
LANGUAGE: Microsoft QuickBASIC
SOURCE
CODE: CLTRMS2K.BAS
COMPILED
SOFTWARE: CLTRMS2K.EXE
SEE ALSO: This program requires and/or generates the
following associated data files. The files contain only ASCII (viewable) data and reside
in the same directories (folders) as the associated executable.
CLTR.NDX -- Index file to CLTR.DAT. An initial file will be created in the working
directory upon first run.
CLTR.DAT -- Reduced data generated by the program. The file contains data from all
saved runs. It is maintained by the program SEDITY2K.EXE.
MS_LABEL.DAT -- Required. The filename is spelled that way. This is a list
of parameter names for the Multisizer II currently in use.
MSII.DAT -- Required in order to use the test option (3) on the input port option
menu (MSII=msii in lowercase).
INPUT: At
the beginning of the first run, the operator will be prompted for diagnostics, printed
output, and printer setup. Subsequently and for each sample thereafter the operator will
be prompted for operator, requestor, cruise id, project id, sample id, lab number, and
tube diameter.
OUTPUT: A
raw data record stored to disk and a hard copy (Fig. 17)
USAGE: To use the program from DOS, change to the working
directory and type: CLTRMS2K
To use the
program from Windows 95/98, access it from the file manager or the Run command
For each
analysis enter:
a) Operator
b) Requestor
c)Cruise id
d) Project id
e) Sample id
f) Lab Number
g) Tube diameter
h) Initial micron diameter
Press the Print/Plot button on the
EMPSA after the analysis is complete and the “Waiting For Sample” prompt is
given.
A copy of
the identifiers and raw data are generated on the printer.
The operator may then save, reprint,
or, if the data are no good, purge the data. Upon responding to any of the three choices,
the program is recycled.
A default (carriage return) to any of
the prompted identifiers other than sample id or Lab Number will enter the identifier from
the previous analysis.
RESTRICTIONS:
This program runs only with output from a Beckman-Coulter Electronics Multisizer IIe
EMPSA. Operator, requestor, cruise id, and project id may be up to 19 characters and have
no imbedded spaces or commas. Speed requirements necessitate the BASIC source code be
compiled into machine language.
AUTHOR/MAINTENANCE: Eliason Data Services, Mashpee, MA/L. Poppe,
USGS, Woods Hole, MA
6.) SEDITY2K
NAME:
SEDITY2K
TYPE: Main
program
PURPOSE: To
archive the raw RSA and EMPSA data into master files subsequently used by the processing
programs. SEDITY2K also examines, edits, and generates additional hard copies of these records.
OPERATING
SYSTEM: DOS version 3.0 or later, or DOS under Windows 3.1/95/98
SOURCE
LANGUAGE: Microsoft QuickBASIC
SOURCE
CODE: SEDITY2K.BAS
COMPILED
SOFTWARE: SEDITY2K.EXE
SEE ALSO: This program requires and/or generates the
following associated data files. The files contain only ASCII (viewable) data and reside
in the same directories (folders) as the associated executable. There are no required
initialization files.
CLTR.DAT -- The user will specify the data file name & location.
CLTR.NDX -- The program will modify the index file as appropriate to the tasks
performed.
RSA.DAT -- The user will specify the data file name & location.
RSA.DAT -- The program will modify the index file as appropriate to the tasks
performed.
SEDXFER.DAT -- The program will create a new data transfer file.
SEDXFER.OLD -- Before rewriting the transfer file, the program will archive the
last transfer file in case of problems.
INPUT: RSA
and EMPSA raw data records, which are stored to disk during operation of the RSA2000 and
CLTRMS2K programs, are input into files accessed by SEDITY2K
OUTPUT:
Master files of raw RSA (Fig. 24)
and EMPSA (Fig. 25) data records stored to disk or a hard copy of the
raw-data records. Note: the first line of each master file is a user-supplied project
identifier that must be removed before the sorting routines are applied.
USAGE: To
use the program from DOS, change to the working directory and type: SEDITY2K
To use the
program from Windows 95/98, access it from the file manager or the Run command
User is prompted for which raw data
records (RSA, EMPSA, or both) are to be accessed. Operations performed by the program are
listed in and selected from the main menu (Table 3). When a number 1 through 7 is
entered, the operator can use that utility to perform the corresponding task.
In the Display or Print mode, the user
can scroll through the list of logged records. This list is composed of Lab Numbers and
letters (O: open, D: deleted, or A: assigned) designating the records present status.
When options 3 or 4 are selected, the
Assign and Edit/Display Mode menu (Table 4) appears and the data records scroll
up from the bottom. The records may be scroll as in the Display or Print modes, but, when
O, D, or A commands are given, the indicated record is tagged for that respective
operation.
When the Edit command (E) is given,
the raw data record for the corresponding Lab Number appears. The user is then prompted
for editing commands.
When all raw data records in the
SEDITY2K files have been written to Master files or deleted, the K key will permanently
remove these records from disk.
AUTHOR/MAINTENANCE: Eliason Data Services, Mashpee, MA/L. Poppe, USGS,
Woods Hole, MA
APPENDIX B. SOFTWARE DOCUMENTATION AND CODE FOR DATA-PROCESSING SOFTWARE
1.) JSORT 11/3/98
NAME: jsort - to sort sediment analyses samples by lab
number and retrieve complete sets which will be appended to the complete data set file.
SYNOPSIS
jsort
file_name
DESCRIPTION: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98 in the Born-Again-Shell (Bash). The program
jsort expects the input file to have a file-name suffix with “.dat”. The “.dat” is not entered on the run line,
but is used solely for file management purposes. The
input file is produced by combining or concatenating the raw data records from the GSANV,
RSAM, CLTRM, and, through SEDITY2K, the RSA2000 and CLTRMS2K programs. The input file is reorganized by 'pack' to contain
one analysis type on only one physical record. This
'packed' file is piped into a) a temporary file "jsortnn" where nn is the
process_id; and, b) into the program 'dirct'. A
directory of which analyses were entered into the input file for each lab number is listed
on the terminal. The listing is piped through
'more'. The original data file “file_name.dat’ is left unaltered.
Upon
completion of the directory listing, the user is queried as to whether the file should be
split. This refers to retrieving complete
data sets from the sorted temporary file. If the user responds 'y' to the prompt
"Enter 'y' to split file:" the complete samples will be copied to a file
'file_name.fin’. If incomplete samples remain, an output file ('file_name.inc') will
be created with only the incomplete samples. If
the file exists, the data are appended to the file. The samples will be sorted and contain
only one physical record per analysis.
The
temporary file “jsortnn" will be purged from the system.
FILES
sedlab.h
SEE ALSO
backup,
dirct, jsplit, sort, tee.
DIAGNOSTICS-BUGS
In the
program 'dirct' the line length is checked. The
program will abort when a packed line has become too large.
See MAXLINE of sedlab.h (2000 chars).
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
2.) GSTAT
NAME: gstat - to retrieve sediment analyses and the
corresponding identifiers from the sorted raw data files and compute standard textural
parameters.
SYNOPSIS
gstat
file_name.out <file_name.fin >file_name.txt
Alternately,
using the provided script file:
dogstat
file_name
DESCRIPTION: This version, which
was written in “c” and compiled with DJGPP (v. 2.01), will run under
Windows 95/98 in the BornAgainShell (Bash). For each sample, the 200-micron tube Coulter
data, 30-micron tube Coulter data, coarse fraction data, and the sample identifiers are
retrieved from the sorted raw data file (file_name.fin) produced by the program JSORT. From these data, the program calculates the
textural distributions (cumulative and frequency percentages); statistics (method of
moments and inclusive graphics; Folk, 1974); percentages gravel, sand, silt, and clay; and
the textural classification. Output is a digital pre-database file (Fig. 26)
and a hard copy (Fig. 21). A
header file has been inserted as the first record in the pre-database file to show the
field attributes and their order. Size
nomenclature and the grade scale are based on the method proposed by Wentworth (1929; Fig. 9);
the classification scheme is modified from the one proposed by Shepard (1954; Fig. 18).
DIAGNOSTICS-BUGS
A message
is displayed which notifies user as each sample is retrieved. During the inclusive
graphics analyses, some distributions cause the last frequency percent to be beyond
100.0%. This will cause a message to be
displayed, which may be ignored. But user
should always "eye-ball" the data for any apparent error(s). If the input file
is out-of-sequence a message will be displayed. This
will be in reference to the sample after the last successfully retrieved sample.
Other
messages, such as core dumped, etc., come from gross errors in input. In such a case, the
input file should be carefully scanned.
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
3.) ENTRY
NAME: entry - to enter sediment data as relative
frequency percents at whole phi intervals.
SYNOPSIS
entry
[-cvgo] file_name
DESCRIPTION: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98 in the Born-Again-Shell (Bash).The 'o'
option allows the user to enter the data as cumulative frequency percent (an ojive). The data must be entered in decreasing values:
i.e., phi [11] = 100%.
The 'g'
option allows the user to enter the data in groups. Each
group (fines, sand or gravel) must sum to 100%.
The default
entry mode is to enter the absolute frequency percent of each phi class. These must sum to 100%.
The user is
prompted for all input. The user will not be prompted for a given group when no data are
present for that group. (Eg., there is no sand in the sample.)
Entry for a
given phi group may be restarted by typing in "re" in response to the phi
prompt. A 'RE' can be entered to restart at phi[11].
If the
"v" option is selected, the phi with corresponding relative frequency percents
are displayed on the screen. If the user
responds "no" to the verification, the group entries are discarded and the user
may re-enter that phi group.
A
"." (period) in response to the phi prompt terminates entry for that phi group.
If the
"c" option is selected, latitude and longitude will be entered as degrees
minutes and hemisphere (N, S, E or W) and will internally be converted to decimal degrees
(+/-). See GSANV write-up for description of
allowed sampling devices and areas.
The sample
is written when all data have been entered for the current sample.
The program
may be aborted at any time by hitting “Control C”
FILES
sedlab.h
gstat.h
SEE ALSO
(make file = entry.m)
LISTA = entry.o getdatm.o rsetup.o getids.o prhead.o getnavm.o output.o
LISTB = getlin.o iolib.o
entry: $(LISTA) $(LISTB)
cc $(LISTA) $(LISTB) -o entry -lm
$(LISTA) $(LISTB): sedlab.h
$(LISTA) $(LISTB): gstat.h
DIAGNOSTICS-BUGS
Each
response will have a maximum field length as specified in sedlab.h . If the user response
is too long, the program will specify the maximum number of characters allowed for the
current response.
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
4.) GSTATM
NAME: gstatm - to input frequency percent data entered
by ENTRY and analyze as described in GSTAT.
SYNOPSIS
gstatm
file.out <file.dat >file.txt
DESCRIPTION: This version of the program, which was written in “c” and compiled with
DJGPP (v. 2.01), will run under Windows 95/98 in the BornAgainShell (Bash). Data are read
from stdin ("file.dat") which was created by the program ENTRY. The relative frequency percentages are normalized
to 100%. These are statistically analyzed by method of moments and inclusive graphics
methods, plotted, and output both in page format as a hard copy (Fig. 21)
and as a comma-delimited pre-database file (Fig. 26). The formatted statistical analyses
and printer plots are directed to stdout ("file.txt"). The pre-database formatted identifiers and
analyses are directed to a file ("file.out").
Size nomenclature and grade scale are based on the method proposed by Wentworth
(1929; Fig.
9). The verbal equivalents are
calculated using the inclusive graphics statistical method (Folk, 1974) and the
classification scheme was modified from the one proposed by Shepard (1954; Fig. 18).
FILES
sedlab.h
gstat.h
SEE ALSO
(make file = gstatm.m)
LISTA = gstatm.o loadat.o loadids.o gprint.o prhead.o getnav.o
LISTB = stats.o name.o momnts.o mode.o hplot.o pgprint.o igst.o iolib.o
LISTC = median.o iqhscu.o icsevu.o
gstatm: $(LISTA) $(LISTB) $(LISTC)
cc $(LISTA) $(LISTB) $(LISTC) -o
gstatm -lm
$(LISTA) $(LISTB): sedlab.h
$(LISTA) $(LISTB): gstat.h
DIAGNOSTICS-BUGS
A message
is displayed which notifies user as each sample is retrieved. During the inclusive
graphics analyses, some distributions cause the last frequency percent to be beyond
100.0%. This will cause a message to be
displayed, which may be ignored. But user
should always "eye-ball" the data for any apparent error(s). If the input file
is out-of-sequence a message will be displayed. This
will be in reference to the sample after the last successfully retrieved sample.
Other
messages, such as core dumped, etc., come from gross errors in input. In such a case, the
input file should be carefully scanned.
AUTHOR/MAINTENANCE
Janet J.
Fredericks, WHOI, Woods Hole, MA/Larry Poppe, USGS, Woods Hole, MA
5.) CLAYES2K
NAME: CLAYES2K - to extrapolate the clay
fraction to the colloidal clay boundary
TYPE: Main program
PURPOSE: This program will calculate
that portion of the clay fraction not detected during a particle-size analysis by a
Coulter Counter (down to 13.0 phi). The
operator may select linear or exponential extrapolation, or the mean of both (Fig. 22).
OPERATING
SYSTEM: DOS version 3.0 or later, or
DOS under Windows 3.1 or Windows 95
SOURCE
LANGUAGE: Microsoft QuickBASIC version
4.0 or later
Library-standard
SOURCE
CODE: CLAYES2K.BAS
COMPILED
SOFTWARE: CLAYES2K.EXE
INPUT: The pre-database file created
by GSTAT, the main data processing and statistics program used in the Sedimentation
Laboratory of the Coastal and Marine Geology
Program, Woods Hole Section. The format for this pre-database file and an example of a
typical file is shown in figure 26.
OUTPUT:
When specified, this program will generate a hard copy (Fig. 27)
and/or a data file (Fig. 28).
The optional hard copy will contain: the sample identifiers; the original and
revised frequency percentages; the original and revised percentages of gravel, sand, silt,
and clay; a revised sediment classification (verbal equivalent); and the revised
statistics. All sample identifiers of length greater than 11 characters will be truncated.
The optional data file will be comma delimited and contain: the sample identifiers;
the revised percentages of sand, gravel, silt, and clay; the revised verbal equivalent;
the revised statistics; and the revised frequency percentages (-5 to 13 phi). The first line of this data file will contain a
list of the field attributes.
USAGE: To use the program from DOS, change to the working
directory and type: CLAYES2K
To use the
program from Windows 95/98, access it from the file manager or the Run command.
The program CLAYES2K is interactive and will prompt the operator for:
1.) A printer output on LPT1 (the
default is no).
2.) Which to use: linear or
exponential interpolation or the mean of both
(the default is the mean). Linear
interpolation may slightly over-estimate the amount of clay present; exponential
interpolation may slightly under-estimate the amount of clay present.
.
3.) The smallest particle size in
microns actually measured.
4.) The drive where the data file is
located (the default is C:).
5.) The path name to the data file.
6.) What filename to read. If none is
entered, the program will display a directory of the file names in the specified drive and
path.
7.) The initial Lab Number. If no lab
number is entered the program will search for the first lab number in the specified file.
8.) Whether to write the revised data
to disk (the default is yes). The program
will add an “E_”, “L_”, or “M_” depending on which
interpolation is chosen to the beginning of the filename assigned to the output file. If the resultant filename is too long (over eight
characters), the user will be warned and asked to enter a new file path and name.
9.) Whether the operator wishes to pause the scrolling screen after each record in
order to examine the data.
AUTHOR/MAINTENANCE: Eliason Data Services, Mashpee, MA/L. Poppe,
USGS, Woods Hole, MA
APPENDIX C. COMPUTER PROGRAMS
All programs are stored in a directory labeled software. To access these programs,
go to the software directory, and down-load the desired software.
BASIC
SOFTWARE
The following programs were written and the executables compiled into machine
language with Microsoft QuickBasic (version 4.5). They will run under DOS version 3.0 or
later, or DOS under Windows 3.1/95/98. The source code module names have a BAS
extension; the compiled executables have the extension .EXE.
Software Compilation and Source Code:
RSA2000.BAS
CLTRMS2K.BAS
SEDITY2K.BAS
CLAYES2K.BAS
Executable Programs:
RSA2000.EXE
CLTRMS2K.EXE
SEDITY2K.EXE
CLAYES2K.EXE
The above programs require the following data files. The files contain only ASCII
(viewable) data and reside in the same directories (folders) as the associated executable.
ADAC.DAT
RAWINDEX.DAT
MIXED_AD.LIB
MIXED_AD.QLB
MS_LABEL.DAT
MSII.DAT
C LANGUAGE
SOFTWARE
The following programs were written in “C” and compiled with DJGPP
(version 2.01) to run on Windows 98 with the GNU operating system installed and run from
the Born-Again-Shell (bash), which is run in a DOS-prompt window. These programs
include the data-acquisition software: GSANV, RSAM, CLTRM, and ENTRY, and the
data-processing software: JSORT, GSTAT, and GSTATM. The DJGPP is a 32-bit
protected-mode development system available from Walnut Creek CD-ROM (ISBN 1-57176-228-0)
that is suitable for porting Unix programs to DOS. GNU
is a Unix-like operating environment distributed by the Free Software Foundation (ISBN
1-882114-57-4). The user must install the GNU
package, and set their system to run in the bash environment before using these programs.
Software Code: Documentation files and source code are contained in the compressed
file:
c_code.tar
Download the
tar file to an appropriate directory. This tar file, which puts
it’s contents into a new directory called c_code, is expanded in the bash shell
with the command:
tar xvf c_code.tar
Executable Programs: Compiled versions of the code and a readme file are contained
in the compressed file:
apsas_up.tar
Download the
tar file to an appropriate directory. This tar file, which puts
it’s contents into a new directory called apsas, is expanded in the bash shell
with the command:
tar xvf apsas_up.tar
The
programs may be operated from this directory or can be copied to a directory which is in
the user’s path.
Questions
regarding these utilities (not the DJGPP or Free Software Foundation packages and the
Unix
environment) should be directed to lpoppe@usgs.gov and include "regarding Unix
package" in the subject. Questions regarding installation and implementation of DJGPP
or the GNU utilities should be directed to Walnut CD-ROM and the Free Software Foundation,
respectively.
Return to Table of Contents
Continue to Database Section
[an error occurred while processing this directive]
 For many years,
the size and distribution of the sand and
gravel fractions were determined solely by sieve analyses, and silt and clay fractions
were determined by pipette or hydrometer methods. Later,
rapid sediment analyzers (RSA;
For many years,
the size and distribution of the sand and
gravel fractions were determined solely by sieve analyses, and silt and clay fractions
were determined by pipette or hydrometer methods. Later,
rapid sediment analyzers (RSA; 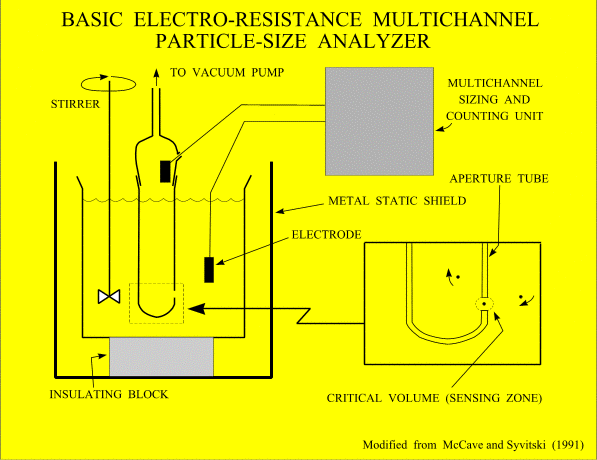 The
commercial availability of inexpensive personal computers
allows sedimentologists to construct complete computerized particle-size analysis systems
(Poppe and others, 1985). The major advantage
of using these systems is
the time-, labor-, and cost-saving functions they afford. Most of the laboratory equipment
and procedures, and all of the data processing described herein may be adapted to
IBM-compatible personal computers.
The
commercial availability of inexpensive personal computers
allows sedimentologists to construct complete computerized particle-size analysis systems
(Poppe and others, 1985). The major advantage
of using these systems is
the time-, labor-, and cost-saving functions they afford. Most of the laboratory equipment
and procedures, and all of the data processing described herein may be adapted to
IBM-compatible personal computers.