Content Metadata Standards for Marine Science: A Case Study, USGS Open-File Report 2004-1002
Title Page
Introduction
Cataloguing
Challenges
Evolution
|
MRIB CASE STUDY |
| 1. Items/Collections |
| 2. Metadata Fields |
| a. Development |
| b. Time/Location |
| c. Revisions |
| d. Collection Facets |
Discussion/
Challenges
Conclusion
References
The MRIB Metadata: A Case Study
NOTE: Library card catalogues (drawers of cardstock slips, each bearing subject headings and other vital data about a particular volume) were once ubiquitous symbols of information organization in the physical world. Because the MRIB is drawing on the concepts of these paper-and-ink metadata records, its metadata records are called "Electronic Index Cards," or EICs.
 |
| Figure 1. The MRIB's item metadata fields. Click on figure for larger image. |
At the heart of the MRIB project is the creation of a metadata standard specialized for representing the marine sciences and for providing access to users of varied technical competence. The discussion that follows will address how this standard has developed and how some of its early mistakes are being corrected. The MRIB case study may serve as an example of how the challenges of specialized-content digital libraries may be met, and the account of pitfalls along the way may be useful in the establishment of other such libraries. More technical information about the actual implementation of the MRIB metadata, such as the computer format in which EICs are stored and how the interface functions, can be found in Marincioni and others (2003). The complete controlled vocabulary lists, metadata dictionaries, a DTD (Document Type Definition used to guide and validate eXtensible Markup Language, or XML, documents) for coding MRIB records in XML, and other supporting documents are stored on the MRIB server at http://www.mrib.usgs.gov/controlled_vocabulary/.
 |
| Figure 2. The additional metadata fields for collections. Click on figure for larger image. |
Although the non-MRIB metadata standards outlined earlier have evolved substantially since the inception of the MRIB, the MRIB has unique metadata needs by virtue of its subject matter and the kinds of resources it catalogues. Metadata fields for the MRIB were required to address the particular needs of Web-based information resources about marine science. The fact that marine science is a broad spectrum of endeavors —which includes work by educators, anthropologists, and historians, in addition to the more obvious natural scientists (such as oceanographers and geologists) —complicated the creation of these metadata fields. Thus the MRIB required a new metadata standard (described in Figure 1 and Figure 2), rather than re-use of other standards. The keystone of this new standard is use of controlled vocabularies wherever conceivably helpful. A controlled vocabulary, that is, the complete list of valid terms for a given facet, facilitates both finding and cataloguing because it ensures that a concept will always be assigned the same classificatory term within an encompassing facet. Additionally, since the set of possible terms within a facet is known, rather than undefined, relationships between terms can be explicitly defined. Hierarchical term relationships are emphasized in the MRIB because they allow the user to adjust the level of specificity for her searching or browsing. Example terms from the controlled vocabulary of each of the item metadata fields appear in Table 1.
Table 1: Examples of Terms from the Controlled Vocabularies of the Facets
ESSENTIAL FACTS
| FACET NAME | EXAMPLE |
|---|---|
| Document Authors | Riall, Rebecca L. rriall@usgs.gov |
| Agencies | Academic Institutions/United States of America/Indiana/Indiana University/Bloomington |
| Content Type | Images/Still/Photographs/Ships and Other Platforms |
| Geologic Time | Phanerozoic/Cenozoic/Tertiary/Neogene/Miocene |
| Collection Name | Mobile Bay Satellite Images |
| Collection Title (collection metadata only) | Gulf Coast Satellite Images/Mobile Bay Satellite Images |
PROCEDURAL FACETS
| FACET NAME | EXAMPLE |
|---|---|
| Projects | Marine Realms Information Bank |
| Methods | Field Observation/Remote Sensing/Aerial Photography |
| Location | (Numerical latitude and longitude are recorded for the study area of the document. The search engine matches these points to named locations that are defined by bounding ranges. Example below is of a named location.)Seas and Gulfs/Americas/North America/Gulf of Maine/ |
CONCEPTUAL FACETS
| FACET NAME | EXAMPLES |
|---|---|
| Disciplines | Geology/Sedimentology |
| Physiographic Features | Landform/Islands/Barrier Islands |
| Biota | Eukaryota/Metazoa/Annelida/Polychaeta |
| Hot Topics | Environment/Environmental Issues Involving Sediment/Sediment Interaction with Pollutants |
Items and Collections
In a physical library, it is customary to catalogue items based on their material presence —a self-contained three-page pamphlet would have a record in the catalogue, while an article of similar length, but contained by a journal, would not. Such "sub-items" as individual articles in a single bound journal would instead be included in subsidiary indices —in this case the periodical index provided by the journal publisher, a separate searchable catalogue of the journal, or a single-discipline catalogue (such as Georef). However, in a digital library, the choices about cataloguing depth, or granularity, are less fixed.
The complexities of granularity choices are perhaps best illustrated by example. For instance, a Web site might host a collection of one hundred seafloor images, with two images on each page. This leaves several possibilities for what components of the whole Web site will be catalogued: 1) Only the main page, which indexes the pages containing the actual images, is catalogued (one record); 2) Each HTML page, with its two images, receives an individual catalogue record (a total of fifty records plus the index record); or 3) Each image receives an individual catalogue record (a total of one hundred records plus the index record). Each of these three selections has its advantages and disadvantages. If only the main page is indexed, then a user who is interested in a very specific location, such as offshore Alabama, would be unable to find the image of that area directly through the catalogue records. On the other hand, if individual HTML pages are catalogued, a searcher who wants to find larger seafloor images, such as an image of the entire Pacific Ocean, might be inundated with irrelevant findings. Cataloguing individual images rather than individual HTML documents could further exacerbate the deluge even as it permitted direct access to the images from the catalogue. One might term the extreme of only one record "very low granularity" and the extreme of 101 records "very high granularity."
The first versions of the MRIB followed a moderate approach toward granularity. In this approach, the MRIB team applied a simple rule: it was acceptable to catalogue any Web page or PDF file that had at least two self-contained items of information. For instance, a photo and a descriptive caption would qualify, while the photo alone would not. The two-items rule served as a metric to eliminate items that had little or no value independent of their context. For example, it precluded the cataloguing of a page that listed only the definition of a single term or an image that was presented with no information about its importance.
The success of this tactic depends partly on the initially-small collection size of some 3,000 records. However, as the MRIB collection has grown, the flaws of this "moderate" approach have become apparent. The chief problem is that is possible for some user searches to return a large number of highly-similar pages. For example, a set of records for 2,000 DODS (Distributed Oceanographic Data System) resources, each with nearly the same metadata profile, flooded the MRIB with difficult-to-distinguish results when they were temporarily introduced. On the other hand, eliminating individual item records from the MRIB in favor of a one-record-per-collection approach would also make valuable items difficult to locate directly from the catalogue.
Two separate sets of metadata records constitute a newer version of the MRIB metadata catalogue —one set for collections of resources and another for individual resource items. An "item" is an individual document (which may combine several different information types, such as images and text, that are viewed as a single unit) such as an HTML page, PDF file, or plain-text file. A "collection" is typically a set of pages intended by their author or authors to form a cohesive aggregate, such as a Web site (collection of Web pages). However, a "collection" might also be a single document on which some fundamentally similar things are collected (such as a single HTML page which includes a series of hundreds of photographs of marsh organisms).
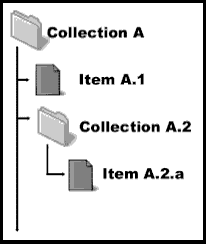 |
| Figure 3. Item and collection "nesting." Click on figure for larger image. |
As part of the newer dual-granularity catalogue, separate item and collection metadata profiles have been specified to describe characteristics unique to each record type and to define hierarchical relationships between 1) items and collections, and 2) collections and their encompassing collections (collections of collections), as illustrated in Figure 3. The MRIB user will be able to choose whether to search only collections or to search individual items. Both metadata profiles include the same facets and fields for subjects and standard bibliographic descriptors. The details of the item and collection profile types and the rationale by which they developed are described below.
The MRIB Item Metadata Fields
 |
| Figure 4. Controlled vocabulary for one facet, Physiographic Features, in action. Click on figure for larger image. |
The MRIB is intended to be a "browsing engine" as well as a search engine.
In fact, the earliest version of the MRIB did not permit searching for user-defined strings, but rather relied wholly on point-and-click browsing of the term lists. The intention to support browsing dictates that possible search subjects in the MRIB must be organized in some logically consistent way. The MRIB team chose to organize concepts into groups of related subjects, with each group containing broader, narrower, and co-level terms. Each top-level group representing major classification criteria (a facet) was assigned its own controlled vocabulary (see Figure 4).
The valid terms for a given facet, constituting its controlled vocabulary, are listed in a term list specific to that facet. Each facet's term list is structured in a database-readable format. The lists store additional information about each term, including a brief definition of the term as it is used in the MRIB and book-keeping data (such as who entered the term, when it was entered, when it was last modified, and whether it has been approved by the MRIB team). The term definitions are especially important, because the terms do not simply record words used in the cataloged documents, but instead represent concepts that, to be precisely defined, often require sentence-length explanations. Explicit term definitions encourage the consistent application of terms that otherwise would be ambiguous because of cross-disciplinary, regional, situational, or other differences in use. It is unavoidable that disciplines will use terms in radically as well as subtly different ways. Similarly, it is unavoidable that scientific and nonscientific users will also use words differently. Definitions of terms as they are used in the MRIB are thus necessary, and may encourage users to reflect on different uses of a word.
The current MRIB item metadata fields can be sorted into four major groupings (Table 1). The first group is the essential facets (Document Author(s), Agencies, Collection Name, Content Type, File Type, and Geologic Time) which are considered the minimal required facets for cataloguing any document (in addition to some fields lacking controlled vocabularies which are described below), because any resource will have these attributes. Authors and Collection Name may, on very rare occasions, be exempted from requirement. A second group contains the procedural facets — Projects, Methods, and Location (although it has a controlled list of terms, location terms that apply to a document are derived from numerical latitude and longitude values rather than by named locations embedded in the document's metadata record) —that describe the research processes which resulted in the document's birth. The third group encompasses the conceptual facets (Disciplines, Physiographic Features, Biota, and Hot Topics) that note the subjects of the document.
The fourth group consists of the free-text descriptors. These are metadata fields that, unlike the facets, lack controlled vocabularies. They are URL, Title, Document Curator(s), Document Last-Updated Date, EIC Indexer, Date of EIC Creation, Date of Last EIC Update, EIC Creator's Comments, Description, Research Start Date, Research End Date, Other Keywords, Elevation (mean, maximum, and minimum values), Latitude and Longitude (mean, maximum, and minimum values; these metadata are also used at the interface level by the Location facet). These metadata provide additional (and in some cases, such as Title, critical) information to the MRIB user, but will naturally vary so greatly that controlled vocabularies for them would not be sensible. Of the free-text metadata fields, URL, Title, Document Curator(s), EIC Indexer, Date of EIC Creation, Date of Last EIC Update, Description, and Other Keywords are always required. It should be noted that Other Keywords stores any terms relevant to the document that cannot be described elsewhere in the EIC.
For instance, the common name of an organism, a geographic name which may not yet be defined in the Location facet, or other terms.
o Development of the MRIB Metadata
The present MRIB structure has evolved from its initial conception based both on the indexing-to-uncover process (which will be explained shortly) and on feedback from users. The original facets in the MRIB metadata standard were Author, Project, Discipline, Issue, Method, Geologic Time, Location, Class, Format, and Agencies. With the exception of Author and Project, the term lists for each facet were seeded with terms commonly used in USGS publications, the NASA Global Change Master Directory, and the Marine Biological Laboratory's Web site. New terms are added to Author and Project ad hoc. Although it might seem simpler to leave these two facets uncontrolled, the use of controlled vocabularies for them makes it more likely that, for instance, an author's works will appear under only one name, regardless of whether some publications give only the author's initials while others use the full name, or whether an author undertakes a legal name change. Similarly, projects may be variably referred to by official titles, acronyms, and informal names, so it is important that only one be used by indexers for a single project.
After this initial seeding, the MRIB EIC collection and controlled vocabulary lists were expanded using an indexing to uncover process, as described by Marincioni and others (2003). This process involves the experimental cataloguing of appropriate marine science information resources (thus creating new EICs) while maintaining lists of new concepts and the terms used by resource authors to describe them. These lists were eventually incorporated into the formal term lists. Although emphasis was placed on adding recurring concepts to the term lists, concepts that had not yet been seen to recur during the indexing were sometimes added because of their likelihood to recur in the future, their interest level, or other factors.
The terms themselves were derived, where possible, from the information resources themselves; when several terms existed for a concept (or when a concept crossed between facets) the least ambiguous and most widely-used terms were privileged. Redundancy was permitted between facets and between trees within each term list, so that a concept might appear in different aspects, in different facets. For instance, the basic concept of sediments appears in the Discipline facet as "Sedimentology" and in the Physiographical Features facet as "Soil." Additionally, the small sets of original terms included in the seed lists were often modified to better reflect common usage or to be more precise.
At times, the basic structure of the categorization scheme itself was significantly revised. In some instances, new facets were created (Biota, Physiographic Features, and Audience); in others, the hierarchy of a facet was totally revised to permit a more consistent and scalable organization. Care was taken to favor revision, rather than to allow the ontology to become mired in trial forms that proved unsatisfactory for the practical tasks of organizing and locating information resources.
The organizational structures that emerged from the indexing-to-uncover process are flexible. New terms can be added easily, and after much indexing the broad categories within most of the facets have become optimized for expansion. It is expected that new methods and new concepts will continually emerge in the marine sciences and related disciplines, so the flexibility is a necessary feature. Certainly at present, new terms are frequently added to the lists.
o Time and Location
It is reasonable to ask how the MRIB team has attempted to especially suit the MRIB metadata standard to marine science. One way is that, through the indexing process discussed above, terms and concepts have been gathered from marine science documents generated by experts, but their inclusion was also tempered with feedback from non-experts. Secondly, Earth science information is usually associated with two major concepts which the MRIB metadata have been made to emphasize: time and location.
Time in the Earth sciences is commonly expressed as a series of large-scale geologic blocks, ranging from the present backward to the Pre-Cambrian. The MRIB Web interface sorts items based on their ranges in this geologic time scale, which are entered in the EICs in the Geological Time facet. Because marine science also deals with significant changes, such as coastal erosion, over smaller-than-geological periods, such as years and decades, the MRIB standard includes metadata specifying data collection dates. However, these metadata do not have controlled vocabularies and will be discussed further later.
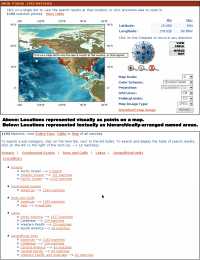 |
| Figure 5. Map view and named locations are two ways the MRIB interface provides the spatial context of information resources. Click on figure for larger image. |
The MRIB interface provides two means to find resources by geographical location: Named Locations (a list-based interface) and Map View (which plots rough locations of resources on an interactive map), shown in Figure 5. Both of these means exploit the numerical latitude and longitudinal values stored by the MRIB metadata fields. Named Locations is considered a facet because it has a fixed (although expandable) list of locations, but, unlike the other facets, its values are not stored directly in metadata records. Instead they are derived from the geographical coordinates which are stored in the records. For instance, an EIC for a resource about Lake Michigan would record the four geographical coordinates of a box around the lake. The MRIB interface would both plot the center of that box in Map View and list the resource as a match for all the Named Locations which overlapped the Lake Michigan bounding box (including Lake Michigan, North America, Indiana, and so on).
That said, there are some problems with matching records to the Named Locations term list. Although its definition of locations by four bounding lines (on the latitude and longitude grid) is simple, the resulting bounding rectangle may become misleading, particularly for large, irregularly shaped geographical features. For instance, a bounding rectangle that encompasses all of the Pacific Ocean also includes much of the Atlantic. This means that, among other misleading results, a record with its central point in Cape Cod will be listed as a "match" for the Pacific Ocean.
Fortunately, one benefit of storing the coordinate data rather than named locations in the records is that these coordinates may be used by newer interface methods and different location lists without requiring modification of the metadata in the EIC. For instance, the Pacific-Cape Cod problem will be remedied in a future MRIB interface revision which permits including bounding polygons in the term list (the solution will not require changes to the metadata database). Thus the problems are with the interfaces to the metadata, and the metadata fields themselves will be compatible with more sophisticated interfaces.
o Major Revisions Along the Way: The Audience, Class, and Format Facets
As mentioned earlier, the categorization scheme was revised when needed during the early development of the MRIB metadata. Eventually, cataloguing and user interaction brought to light essential problems with the Audience, Class, and Format facets. These problems may be useful lessons for the development of other specialized categorization schemes.
 |
| Figure 6. Term lists from the old Facet, Class, and Audience facets. Click on figure for larger image. |
These Audience, Class, and Format facets began with short, fixed term lists (Figure 6). All three suffered from both opaque individual definitions and overlap of purpose. Each of them attempted, from a slightly different angle than the others, to provide information about how a document might be used. However, it is simply not possible to objectively determine each way a document might be used. This is perhaps best clarified by example; we will consider the Audience term "Educator." For some documents, such as one titled "Fourth Grade Lesson Plan on Wetlands," the audience for that document might objectively be noted as "educators." But what of something like an instruction list for using a sonar mosaic processing program? This, too, might serve a specialized "educator" well. Nearly any document might be reasonably expected to serve some kind of educational needs. In an attempt to address this kind of problem-which might be called the problem of explicit versus implicit purposes-the Audience facet was intended only to be used when there was an explicitly-stated audience for a resource (for instance, some resources, such as lesson plans, clearly were intended for teachers, so these would get the "Educator" term). Despite this precaution, early user test groups complained that they thought Audience was an effort to pigeonhole users and limit their browsing choices.
Class proved even more problematic than Audience. Based on interaction with scientists at the USGS, the MRIB developers were aware of scientists' wishes to be able to handily limit their MRIB searches to EICs that described raw data. An early MRIB model of "data" and "not data" posited that documents might be objectively classified by their level of removal from that "pure data" state: they might be data, they might be products derived from data, they might be knowledge synthesized from data analysis, or they might be predictions based on the three preceding stages. Although this model seemed heuristically useful, in practice the heterogeneous, contextual nature of Web documents and the variation of the human mind rendered it useless. For instance, a geological map alone might be considered the derived product of raw data-yet it also, to the extent that it extrapolates beyond the finite set of data points described during mapping, is a visual representation of predictions. Then again, that map might be considered base data for a synthetic map which combines small geologic maps into a larger-area map. Even if the map's creators intended the latter use, would it still be appropriate to rule out the map's other potential uses (as a derived product or as a prediction)? Early on, the MRIB developers realized they could not agree on how to classify some documents. Despite this, the field continued to be applied-but it was no surprise when users, too, found they could not understand how or what the Class of a document meant.
The MRIB team's experience with the Class facet suggests that developers of categorization schemes heed cataloguers' experiences; if cataloguers cannot agree on how to consistently apply a category, that category is likely to pose problems for end-users as well. This is not to imply that a category and its applications will ever be universally agreed-upon, only that it should be agreed upon with some consistency by people of fairly different backgrounds. It may be useful to note the distinction between symbols and signals, as argued by Firth (1973). Firth (1973) notes that a signal is something which "tends to connote some precision of technical consequences" while a symbol connotes "a much more imprecise, open-ended sequence of events and experiences" (p. 66). It is useful to conceive of terms in categorizations schemes as symbols for the characteristics of information resources represented by said terms, rather than signals. Such conceptualization acknowledges that the cultural, situational, and individual experiential factors which color the interpretation of terms-as-symbols are many.
To return to the problematic facets: Format was a problem because its initial term set, unlike the initial term sets of other facets, was not entirely a group of like concepts. It mixed general terms, such as "Image," at the same level with more specific forms, like "Sonar Mosaic" without regard to hierarchy. For a long time, this term list remained a flat, nonhierarchical file, and when hierarchical terms, such as the term "Software" with its child term "Applet", began to be added, the original terms ("Image," "Sonar Mosaic," etc.) were not appropriately reordered to also reflect hierarchy. Additionally, the term list included some terms which were both specific computer file types and general content descriptions (the worst of these being text, which could be interpreted either as a "Plain Text"-formatted file or as any document bearing transcribed human language rather than, say, graphics.
Eventually, through interaction with users, it became more evident that these fields, with their internal inconsistencies and their overlap of one another, were inherently confusing (they were confusing to cataloguers, as well, who could not agree on categorizations). They needed overhaul.
A more clear-cut approach to the basic shared goal of Class, Format, and Audience was found by understanding the common ground among these facets. Each of them was an attempt, however awkward, to describe how a document's author's interpret raw data, with the assumption that some types of interpretation will be more applicable to specific uses than others. A more basic, and thus more objective, way to describe how information was presented by a document would be to note its "file types" (a computer's understanding of file formats, such as "JPEG Image," which could be used to eliminate types of information that a user's computer could not process) and "content types" (a human's understanding of content formats, such as photographs of benthic fauna, bibliographies from scientific reports, etc.). Thus two new facets were developed: File Type and Content Type. Because the terms for these fields represent relatively unambiguous concepts which may be applied consistently among cataloguers, they better met the MRIB's goals of being clear to end-users and encouraging cataloguing by document authors.
A widespread, mature vocabulary for File Type already existed: the Multipurpose Internet Mail Extensions (MIME) types (ftp://ftp.isi.edu/in-notes/iana/assignments/media-types/media-types). The MRIB adopted this standard as the vocabulary for its File Type facet. Since MIME is so well-developed and used in so many applications, creating a new vocabulary for File Type would have been redundant and would needlessly complicate interoperability with other metadata standards. Content Type, on the other hand, was not a basic concept for which an adequate vocabulary existed outside of the MRIB. The nearest semblance to this facet was the Dublin Core's "Type" Vocabulary (described briefly above), which provides ten basic terms such as "Dataset" and "Events." Beginning with the DCMI "Type" term list, terms were eliminated that were not relevant to the MRIB's scope (such as "Physical Objects,"). Next, the vocabulary was expanded downwards, using the Dublin Core type terms as the upper-level categories in a hierarchical term list. Thus, interoperability with the Dublin Core metadata standard is ensured, while the vocabulary still provides more detail-rich information for use by the MRIB and MRIB-compatible systems. As of July 2003, the MRIB's EIC collections are being reworked to remove the Audience, Class, and Format facets and insert File Type and Content Type.
As the need for separate, albeit linked, item and collection metadata standards became evident, an additional facet was created to define hierarchical relationships between items and collections (or subcollections and supercollections). This facet, Collection Name, matches the field Collection Title in the Collection metadata record for the collection that includes the item. For instance, there might be a collection of satellite images of Lake Erie with an MRIB metadata record. Individual HTML documents that comprise the collection might each have their own metadata records as well. Each record for those HTML documents would then list "Lake Erie Satellite Images" as the value of their Collection Name, and the metadata record for the collection would list its Collection Title as "Lake Erie Satellite Images" to complete the link. Since the Collection Name facet is also present in Collection records, a hierarchy of documents within a series of nested collections can be defined. For instance, that Lake Erie photo collection might be part of a larger collection of Great Lakes satellite photos, and might list "Great Lakes Satellite Images" in its own Collection Name (not Collection Title) field. Thus an interface to the MRIB metadata can guide the user from information about a collection to the individual collections or items that comprise it, or the interface may guide the user from a useful page to other pages within the same collection.
The MRIB Collection Metadata Facets
The MRIB metadata standard for collections is similar to that for items, except for a few additional fields (all of them possessed by collection records and absent from item records) which are listed in Figure 2. The Collection Title facet contains the title of the collection that is being indexed. The title is added to a controlled vocabulary list to ensure matching from collection records to the records of the items and/or collections that they contain. (Collection Title is not to be confused with the Collection Name facet; Collection Name defines the collection to which an item or collection belongs, whereas Collection Title is the title of a collection itself. In other words, the distinction is a way to nest collections. This may be understood by analogy to directories in a computer's file system, which may contain other directories as well as individual documents.)
The remaining collection-specific metadata fields are free-text descriptors. One of these, Collection Coverage, describes the collection's subject matter in a brief phrase. Another, Collection Alert, describes any cyclical "downtime," periodic removal of archival data, or similar information about the collection. Item Count describes the number of items within the collection, be they photos, Web pages, PDF files, or other items; this field may be omitted when the collection's nature is such that a count would be impractical or useless (for instance, the www.usgs.gov Web site can be viewed as a collection of Web pages, but it changes so frequently and is so large that a count would be neither useful nor possible). Finally, Update Frequency describes how often the collection is changed, if modifications or additions occur regularly. Ontologically, these fields are all grouped in the free-text descriptors category, except Collection Name, which belongs to the essential facets group.
