

Special Contributing Area Loading Program User’s Manual
Links
- Document: Report (4.0 MB pdf) , HTML , XML
- Software Release: USGS software release —SCALP (Special Contributing Area Loading Program, ver. 1.0.0)
- Download citation as: RIS | Dublin Core
Introduction
The Special Contributing Area Loading Program (SCALP) is a hydrologic routing program that simulates reservoir routing through a linear-reservoir-in-series method. The Java version of SCALP (Domanski and Doyle, 2023) was developed to replicate and replace the functionality of an older version of the program written in Fortran. SCALP models flow through three reservoirs in series using an input runoff depth time series and information describing the hydrologic characteristics and sanitary flow for one or more land areas within a basin, supplied by the user. Each basin is herein referred to as a “Special Contributing Area” (SCA); the SCAs are a central concept in SCALP. Although flow through each SCA is routed separately, the user may simulate multiple SCAs in a batch simulation. The outputs of SCALP include information about flows through and overflows from the three reservoirs in the series.
SCALP simulates reservoir routing through a linear-reservoir-in-series method. Each SCA contains hydrologic characteristics pertaining to its three reservoirs in series, land areas within the SCA, and sanitary flows from the population that contribute to the basin. Three components of inflow are defined for each SCA: stormwater flow, sewer infiltration, and sanitary flow. Each land area, also referred to as a “land segment,” contains three tributary area types (pervious, impervious, and subsurface) and requires three runoff depth time series as inputs (overland flow runoff [OLFRO], impervious runoff [IMPRO], and subsurface runoff [SUBRO]). Using the three tributary area types and the three input runoff depth time series, the stormwater flow and sewer infiltration are computed for each land segment. Stormwater flow time series are computed for each time step by
whereINFLO
is the stormwater flow, in cubic feet per second;
OLFRO
is the overland runoff, in inches per hour;
PA
is the pervious area, in square miles;
IMPRO
is the impervious runoff, in inches per hour; and
IMPA
is the impervious area, in square miles.
SANIT
is the sanitary flow,
PE
is the population equivalence,
HFF
is the hourly flow factor,
WFF
is the weekly flow factor, and
MFF
is the monthly flow factor.
For each SCA, the stormwater, sewer infiltration, and sanitary flows are routed through three sewers represented in SCALP by three linear reservoirs in series. The three sewers are herein referred to as “lateral,” “submain,” and “main” sewers, where the lateral sewer is first, the submain sewer is second, and the main sewer is third in the series. Each sewer is characterized by a routing coefficient, maximum flow, a stop store flag, and split flow. The routing coefficient is the proportionality constant of the linear relation between reservoir storage and outflow determined empirically for each reservoir. The maximum flow parameter is the maximum volume of flow that can be routed through a sewer; any volume of flow exceeding the maximum flow is either lost from the sewer system or stored until it can be released, and the stop store flag determines this behavior. The usage of the stop store flag parameter is described in further detail in the “Special Contributing Area Input Block” section. The split flow parameter defines sewer overflow; flows through a sewer exceeding the split flow are routed to sewer overflow, and flows less than the split flow value are routed through the sewer system. Outflows from the lateral reservoir are routed to the submain reservoir, and outflows from the submain reservoir are routed to the main reservoir. The time series of outflow from the main sewer and overflow from the system are written to a Hydrologic Engineering Center-Data Storage System (HEC–DSS) file, and qualitative descriptions of the SCALP routing process are written to a text-based log file.
Inputs to SCALP include runoff depth time series and a user-defined text file. The input runoff depth time series must be formatted as an HEC–DSS file as described in the “Hydrologic Time Series Input” section, and the text file must follow the format outlined in the “Special Contributing Area Inputs” section. Similarly, the outputs of SCALP are outflow time series contained in an HEC–DSS file and an output log contained in a text file; each is described in the “Model Results” section. Instructions to run single and batch SCALP simulations are provided in the “Installation” section.
Reservoir Routing
For each of the three linear reservoirs in series, SCALP determines the outflow from the reservoir as a function of the inflow to the reservoir and the reservoir’s routing coefficient. A fourth-order Runge-Kutta (RK4) method (Runge, 1895; Kutta, 1901) is implemented in SCALP, and the equations governing outflow from a linear reservoir using this method are described in this section.
Linear Reservoir
The time rate of change of the storage of water in a system is related to the net inflow and outflow of water by (Chow and others, 1988)
whereS
is the storage, or volume, of water in a system, in cubic feet;
t
is time, in seconds;
I
is the net inflow to the system, in cubic feet per second; and
Q
is the net outflow from the system, in cubic feet per second.
K
is the storage coefficient of the reservoir, in seconds (Pedersen and others, 1980).
Integration Methods
SCALP uses the RK4 integration method to solve the system of three ODEs for the three linear reservoirs in series. First, a pass-through integrator is defined, which sets the outflow from the reservoir equal to the inflow at each time step,
for n=0, 1, 2, 3, …This integration method is used for reservoirs in which the storage coefficient K is equal to zero; that is, there is no delay between flow entering the reservoir to flow leaving the reservoir.
For a reservoir with a nonzero storage coefficient K, a Runge-Kutta method is used. A first-order Runge-Kutta method is Euler’s method; in this approach, the rate of change of Q is assumed to follow the function for Q closely for a small timestep (Euler, 1768),
for n=0, 1, 2, 3, …, whereΔt
is the timestep, in seconds; and
f
is the time rate of change of Q, determined by equation 6.
Δt
is the timestep, in seconds; and
f
is the time rate of change of Q, determined by equation 6.
The Euler method and the RK4 method are both Runge-Kutta methods: they select an interval, compute a representative time rate of change of Q using the value of Q at the start of the interval, and then determine the value of Q at the end of the interval. These methods assume that the value of Q at the end of the interval is on the actual (unknown) curve for Q, which can then be used as the starting value for the next timestep. The approximated curve does not perfectly follow the actual (unknown) curve for either method; however, given a small timestep and a finite interval of computation, the difference between the approximated curve and the actual (unknown) curve can be minimized. The Euler method is a simple approximation; because the RK4 method improves the accuracy of the approximated curve with low additional computational cost, it is implemented in SCALP.
Usage
SCALP is written in Java and depends on a Java library developed by the U.S. Army Corps of Engineers Hydrologic Engineering Center to operate with the HEC–DSS input and outputs. This section details the installation process for SCALP, how to run a SCALP simulation, and the inputs that are required (a runoff depth time series and a user-defined text file).
Installation
The SCALP executable Java Archive file and source code in a compressed ZIP file can be downloaded from the U.S. Geological Survey Source Code Archive (https://code.usgs.gov/water/SCALP/-/releases; Domanski and Doyle, 2023). To run SCALP simulations, first download and save the directory “scalp-1.0.0-jre-win_amd64.zip” from the source code archive. Then, extract the contents of the compressed directory to a new folder and save the desired input runoff depth time series and user-defined text file to this folder (refer to “Hydrologic Time Series Input” and “Special Contributing Area Inputs” sections, respectively). Then, run the commands in Windows Command Prompt, shown in figure 1 for a single simulation and figure 2 for multiple (batch) simulations, using path names as follows: “path-to-lib32-or-lib64” is the path to the “lib32” or “lib64” directory being used (users can use the “lib32” or “lib64” directories included in the downloaded files), “path-to-jre-or-jdk” is the path to the directory of the Java installation (users can use the “jre” directory included in the downloaded files), “path-to-scalp-jar.jar” is the path to the executable SCALP Java Archive file downloaded from the archive, “path-to-input-runoff-depth-time-series.dss” is the path to the input runoff depth time series as an HEC–DSS file, “path-to-output-outflow-time-series.dss” is the path at which SCALP will save the output outflow time series as an HEC–DSS file, “input.txt” is the path to the input user-defined text file, and “output.txt” is the output log as a text file. Note that for batch simulations, different input and output files can be specified for each simulation. The outputs of a SCALP simulation are described in further detail in the “Model Results” section.

Example command line arguments used to run a single Special Contributing Area Loading Program simulation in Windows Command Prompt.

Example command line arguments used to run multiple Special Contributing Area Loading Program simulations that share the same input runoff depth time series file and output outflow time series file, in Windows Command Prompt.
Hydrologic Time Series Input
One of the inputs to SCALP is a runoff depth time series formatted as an HEC–DSS file. Hydrologic Engineering Center-Data Storage System Visual Utility Engine (HEC–DSSVue), a Java-based program designed for working with data in an HEC–DSS database file, was used to visualize the example SCALP HEC–DSS input file described in this section. Downloads and more information on HEC–DSSVue are available at https://www.hec.usace.army.mil/software/hec-dssvue/.
The input runoff depth time series file must be formatted as an HEC–DSS database file. For each land segment used in the SCAs of an input file, the runoff depth input file must contain three time series: IMPRO, OLFRO, and SUBRO depth. An example input runoff depth time series that contains the appropriate time series for four land segments is shown in figure 3. The HEC–DSS path parts are shown in figure 3 as the table headings; parts A, B, and F are read by SCALP, and each time series must have a unique combination of these parts. Although part D is not used by SCALP, it must contain dates in “DDMMMYYYY” format (DD is day; MMM is month; YYYY is year) to be compatible with the javaHeclib dependency, as shown in figure 3.
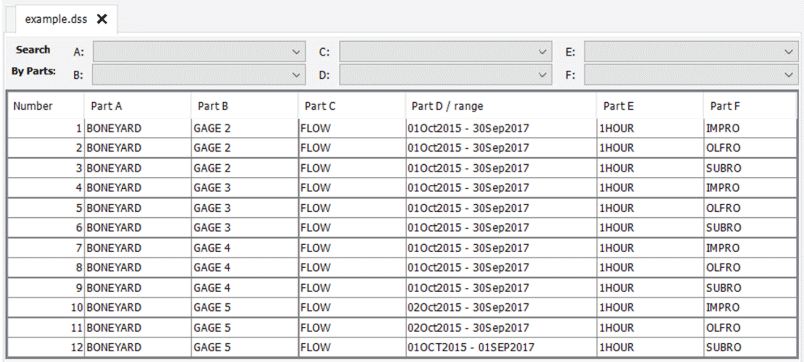
Example input runoff depth time series file viewed in Hydrologic Engineering Center-Data Storage System Visual Utility Engine.
Each time series in the input HEC–DSS file should contain 1-hour average runoff data reported at the end of each hour, in inches. An example SUBRO time series for the period ranging from October 1, 2015, to September 30, 2017, is shown in figure 4, plotted and tabulated in HEC–DSSVue.
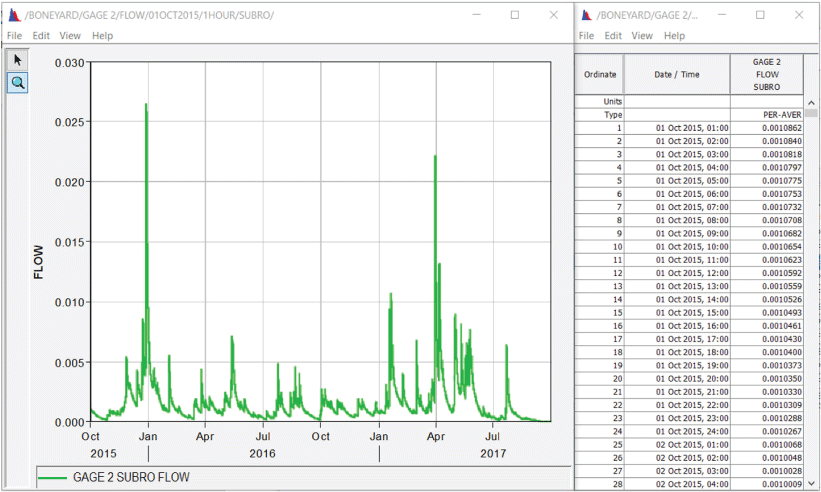
Example subsurface runoff depth time series plotted and tabulated in Hydrologic Engineering Center-Data Storage System Visual Utility Engine.
Special Contributing Area Inputs
Information pertaining to each SCA that the user wishes to simulate must be contained in a user-specified text input file. SCALP requires that the information be formatted according to the format presented in this section; SCALP will not complete a successful simulation if the format is not followed. The user input file consists of three input blocks: the “watershed” input block contains the start and end date of the simulation and information about land segments, the “sanitary” input block contains information about sanitary flow, and the “SCA” input block contains information about each SCA to be simulated. A user input file contains one type of each input block; figure 5 shows an example input file in its entirety, and each input block is described in further detail in this section. Comment lines, which begin with +++, are ignored by SCALP and do not affect simulations. In the following figure and tables, spaces are represented by a middle dot character.

Example user-defined text input file. Spaces are represented by a middle dot character.
The SCALP user input file contains information for simulating runoff through SCAs. The current version of SCALP is designed to work with the legacy user input file format, which uses Fortran style formatting. The convention specifies the number of fields, the field type, and the character width of the field; table 1 identifies each field type indicator and its type. For instance, “3I8” indicates three fields on one line, each with a width of eight characters, that are parsed as three distinct integers. If the number of fields is unspecified, it is understood to be one. For example, “A9” indicates one field, parsed as characters, with a width of nine characters. If the field width is unspecified, the number of characters is understood to be one; for example, “16X” indicates 16 fields, which are ignored, each with a character width of 1. Multiple field descriptions, separated by a comma, can be used on a single line. For example, “I8,A72” describes two fields on one line. The first field is parsed as 1 integer with a character width of 8, and the second field is parsed as characters and has a field width of 72.
Watershed Input Block
The watershed input block contains information about the start and end dates of the simulation and the land segments used in the file’s SCAs. The watershed input block in figure 5 is contained in lines 1–16, and table 2 details the formatting of each section and element in the watershed input block. In tables 2–4, the block, section, and element columns contain example text for the input file, and the format and comment columns describe the text and its format. Numerical values used in the element column are representative and should reflect the parameters of each specific simulation.
The “WATERSHED” keyword starts the watershed input block, and “+++” denotes an optional comment line that is ignored by the program. For the “TIME SPAN” element, only one starting date and one ending date should be specified, and these dates should be encompassed within the date range of the hydrologic time series input. The “OUTPUT LEVEL” is a feature of the legacy program in Fortran and is not used in this version of SCALP; however, these lines must be included to accommodate the legacy input file format. Lastly, the “DATA” section contains land segment numbers and corresponding HEC–DSS paths of the input runoff time series. All land segments used in the SCAs for this file must be specified in this “DATA” section; multiple land segment numbers can be specified by separating each number onto a new line. In each line defining a land segment, the first field, parsed as an integer, must be a unique land segment number. The second field, parsed as a character string, is a short form of the corresponding HEC–DSS path identifying the A and B fields of the path. The HEC–DSS paths of the time series correspond to the paths of records contained in the input HEC–DSS file, which is specified on the command line call of SCALP. SCALP expands the short form of the path to three full HEC–DSS paths that identify the IMPRO, OLFRO, and SUBRO runoffs as part F of the HEC–DSS path. The example in table 2 lists a land segment that has a number of 2 and HEC–DSS path part A of “BONEYARD” and part B of “GAGE 2.” The watershed input block must end with the “END” keyword.
Table 2.
Watershed input block formatting.[--, no data or not applicable; +++, denotes optional comment line; ·, denotes a space; HEC–DSS, Hydrologic Engineering Center-Data Storage System]
Sanitary Input Block
The sanitary input block consists of one or more sanitary information sets that define the creation of sanitary flow time series. SCALP uses sanitary information sets to compute a time-varying sanitary flow per person, which is then converted to total sanitary flow for the population of an SCA. The sanitary input block is contained in lines 18–28 in figure 5 for a single sanitary information set, and table 3 contains details for the formatting of the sanitary input block.
Table 3.
Sanitary input block formatting.[Times are given in military time. --, no data or not applicable; ·, denotes a space]
The “SANITARY” keyword starts the sanitary input block, followed by sanitary information sets. Each sanitary information set defined in an input text file must have a unique identifying number specified on the line that begins with the “SNA#” keyword. The next line contains the sanitary flow per person in the SCA expressed as a scientific number. The following two lines contain monthly sanitary flow factors: the first line contains the flow factors for January through June, and the second line contains the flow factors for July through December. The line after the monthly flow factors contains the weekday flow factors; seven fields contain the weekday flow factors for Sunday through Saturday. The next four lines contain hourly flow factors for each hour of the day (listed as the ending time; for example, 0100 refers to 0000 to 0100): the first line, “01–06AM,” contains the flow factors for 0100 through 0600 hours, the second line, “07AM–12PM,” for 0700 through 1200 hours, the third line, “01–06PM,” for 1300 through 1800 hours, and the last line, “07PM–12AM,” for 1900 through 2400 hours. If multiple sanitary information sets are specified, the next line begins the next information set with the “SNA#” keyword and the unique set number, followed by the flow factors. The sanitary input block ends with the “END” keyword, which must be present.
Special Contributing Area Input Block
Finally, the SCA input block is the last block in the user input file. This block contains information for each SCA in the simulation pertaining to the sewer inflows and characteristics. In the example in figure 5, the SCA input block is contained in lines 30–61, and table 4 details the formatting necessary for the SCA input block. The SCA input block begins with the keyword “SCA” and must contain one or more SCA definitions. The definition of an SCA begins with the keyword “ANALYSIS” and ends with the keyword “EXECUTE”; multiple SCAs can be separated by new lines, and the “FINISH” keyword indicates to SCALP that there are no more SCAs to simulate. An SCA is defined by a unique SCA number and area, land segments, sanitary information set numbers and SCA population, reservoir routing characteristics, and output time series file location.
Immediately after the “ANALYSIS” keyword, the SCA number and area fall on a single line beginning with the keyword “SCA#,AREA=” and containing a unique SCA number and total SCA area. The SCA area is a floating-point number that represents the total SCA area, in square miles. Land segments are specified for the SCA beginning with the “LANDS” keyword and ending with the “END” keyword. Each line in the “LANDS” section must contain the unique identifier for the land segment (which must also be present in the watershed input block) and three floating-point numbers that correspond to the impervious, pervious, and subsurface tributary areas, in square miles. Multiple land segments can be specified by separating each land segment by new lines. The sanitary flow contribution section is denoted by the “SANITARY” keyword and ends with another “END” keyword. For each sanitary flow contribution for the SCA, a line beginning with “SNA#,PE#” contains the unique sanitary information set number (which must be present in the sanitary input block) and the total population equivalent of the sanitary flow contribution, in number of people. Multiple sanitary flow contributions may be specified, separating each by a new line.
The routing scheme that SCALP implements uses three linear reservoirs in series that represent the three sewers: lateral, submain, and main. Routing information is specified for each sewer type, including initial flows, an overflow indicator, routing constants, maximum flow, and split flow. These characteristics are defined in the routing information section, which begins with the “INITIAL FLOWS” keyword, and all the following fields specify characteristics for the three sewers—lateral, submain, and main—respectively. Initial flows through each sewer are specified on the line beginning with the keyword “OUT1(*)=,” in cubic feet per second. This line is followed by the “ROUTING” keyword. Next, the line containing the “STOPSTORE=” keyword indicates, for each reservoir, whether excess flows are to be stored or lost from the sewer system. “NO” indicates that excess flows are to be stored; “YES” indicates that excess flows are to be lost from the system entirely. The line starting with the keyword “RK(*)=” defines the routing constants for each reservoir, in seconds. Then, the lines starting with “QMAX(*)” and “SPLIT(*)” define the maximum flow and split flow through each reservoir, respectively, whose functionalities are defined in the “Introduction” section.
The “OUTPUT” section of the SCA input block contains summation indicators and corresponding HEC–DSS paths of output sewer flows and overflows. The first field specifies the summation indicator, which is not used and is only included to support the legacy input text file format. The second field, parsed as a character string, is a short form of the corresponding HEC–DSS path identifying the A, B, and F fields of the path. Part F of the HEC–DSS path is not necessary to specify; SCALP expands the short form of the path to three full HEC–DSS paths that identify the IMPRO, OLFRO, and SUBRO runoff as part F. Each defined SCA ends with the “EXECUTE” keyword, and the SCA input block must end with the “FINISH” keyword.
Table 4.
Special Contributing Area input block formatting.[SCA, Special Contributing Area; --, no data or not applicable; HEC–DSS, Hydrologic Engineering Center-Data Storage System]
Model Results
SCALP outputs a hydrologic time series and a descriptive text file at the end of each simulation. This section describes how to read and interpret these results.
Hydrologic Time Series Output
Similar to the runoff depth time series input, the output outflow time series from a SCALP simulation is formatted as an HEC–DSS database file. For each SCA simulated, eight time series are generated by SCALP; figure 6 shows the hydrologic output viewed in HEC–DSSVue for an example simulation with a single SCA. For files with multiple SCAs, the output files for each SCA can be identified by the path parts A and B specified in the SCA input block in the input text file, as described in the “Special Contributing Area Inputs” section. Part F for each time series contains a prefix and a suffix: the prefix indicates whether it is the sewer overflow (“OVF” in fig. 6) or the sewer treatment plant flow (“STP” in fig. 6), and the suffix indicates the constituent of the flow. The total flow (“TOTAL” in fig. 6) is the sum of the three constituents: sewer infiltration (“INFIL” in fig. 6), stormwater flow (“INFLO” in fig. 6), and sanitary flow (“SANIT” in fig. 6).
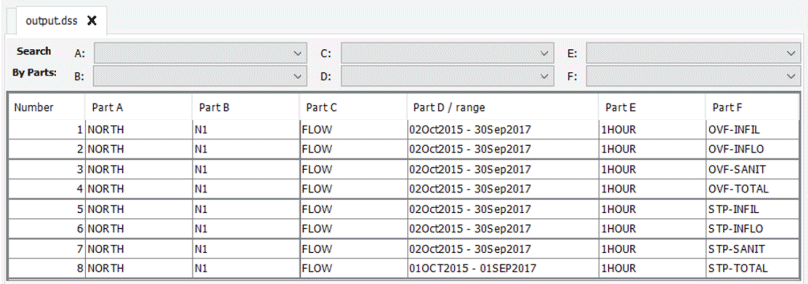
Example output outflow time series file viewed in Hydrologic Engineering Center-Data Storage System Visual Utility Engine. [OVF, sewer overflow; STP, sewer treatment plant flow; TOTAL, total flow; INFIL, sewer infiltration; INFLO, stormwater flow; SANIT, sanitary flow]
Each time series in the output outflow time series HEC–DSS file contains 1-hour instantaneous runoff data, in cubic feet per second. An example SUBRO time series for the period ranging from October 2, 2015, to September 30, 2017, is shown in figure 7, plotted and tabulated in HEC–DSSVue. The figure also shows the same data for a 24-hour period to provide a clearer depiction of the constituent and total flows.
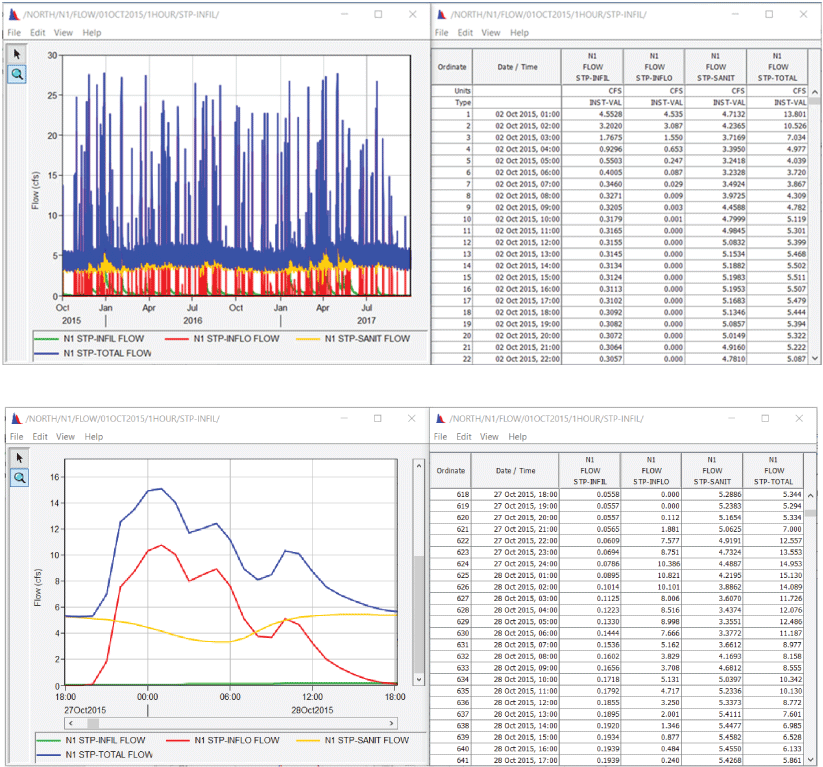
Example output sewer flow time series plotted and tabulated in Hydrologic Engineering Center-Data Storage System Visual Utility Engine for the period ranging from October 2, 2015, to September 30, 2017 (top), and for a 24-hour period ranging from October 27, 2015, at 1800 hours to October 28, 2015, at 1700 hours (bottom).
Descriptive Text Output
For every SCALP simulation, a descriptive output log is generated and saved as a text file. This file contains descriptive text, including a copy of the command line arguments and input file as read by SCALP, the land segment input HEC–DSS paths, and the output HEC–DSS paths. An example output text file is shown in its entirety in figure 8A and B; comment lines in the input file, which begin with “+++,” are ignored by SCALP and do not appear in the output text file. In figure 8A and B, spaces are represented by a middle dot character.
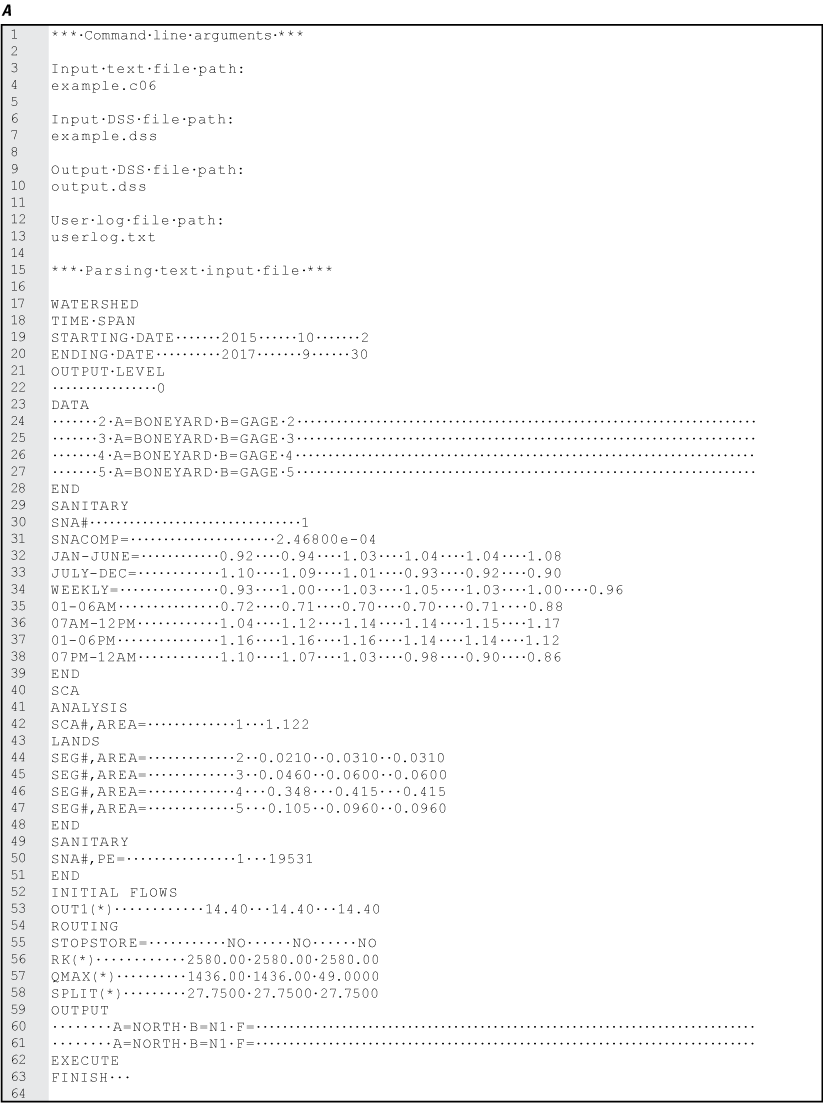
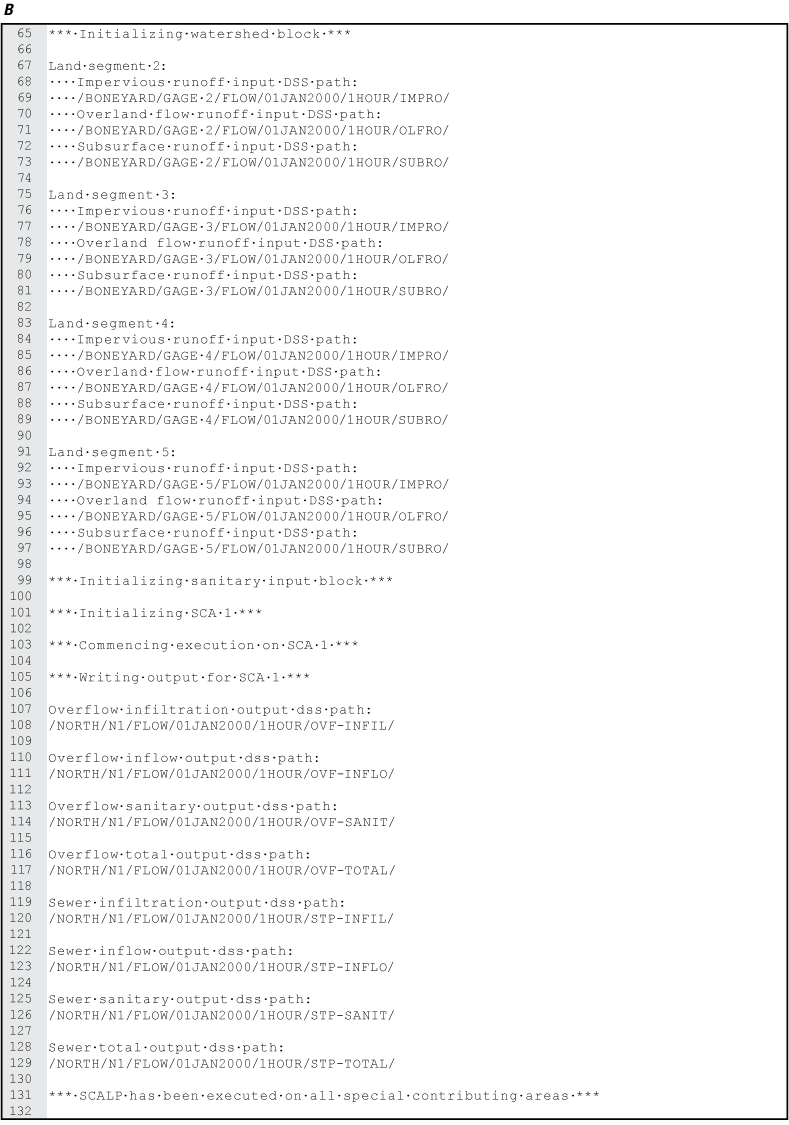
Example output text files. A, part one, showing the command line arguments and input file as parsed by Special Contributing Area Loading Program; B, part two, showing the input and output Hydrologic Engineering Center-Data Storage System paths. Spaces are represented by a middle dot character.
Summary
The Special Contributing Area Loading Program (SCALP) is a hydrologic routing program that simulates reservoir routing through a linear-reservoir-in-series method. SCALP models flow through three reservoirs in series using an input runoff depth time series and information describing the hydrologic characteristics and sanitary flow for one or more land areas within a basin, supplied by the user. To run a successful SCALP simulation on one or more Special Contributing Areas, the user must supply a hydrologic time series and descriptive text file pertaining to each Special Contributing Area, in the formats detailed in this report. Upon completion of a successful SCALP simulation, the program outputs hydrologic time series and a descriptive text file containing the model results. The output time series contain flows through and overflows from the three reservoirs in the series, and the text file contains input and output path locations.
References Cited
Domanski, M.M., and Doyle, H.F., 2023, SCALP (Special Contributing Area Loading Program, ver. 1.0.0): U.S. Geological Survey software release, accessed December 8, 2023, at https://doi.org/10.5066/P9EE0614.
Runge, C.D.T., 1895, Ueber die numerische Auflösung von Differentialgleichungen: Mathematische Annalen, v. 46, no. 2, p. 167–178. [Also available at https://doi.org/10.1007/BF01446807.]
Conversion Factors
U.S. customary units to International System of Units
Abbreviations
HEC–DSS
Hydrologic Engineering Center-Data Storage System
HEC–DSSVue
Hydrologic Engineering Center-Data Storage System Visual Utility Engine
IMPRO
impervious runoff
ODE
ordinary differential equation
OLFRO
overland flow runoff
RK4
fourth-order Runge-Kutta
SCA
Special Contributing Area
SCALP
Special Contributing Area Loading Program
SUBRO
subsurface runoff
For more information about this publication, contact:
Director, USGS Central Midwest Water Science Center
405 North Goodwin
Urbana, IL 61801
217–328–8747
For additional information, visit: https://www.usgs.gov/centers/cm-water
Publishing support provided by the
Rolla Publishing Service Center
Disclaimers
Any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
Although this information product, for the most part, is in the public domain, it also may contain copyrighted materials as noted in the text. Permission to reproduce copyrighted items must be secured from the copyright owner.
Suggested Citation
Doyle, H.F., and Domanski, M.M., 2024, Special Contributing Area Loading Program user’s manual: U.S. Geological Survey Open-File Report 2024–1021, 15 p., https://doi.org/10.3133/ofr20241021.
ISSN: 2331-1258 (online)
| Publication type | Report |
|---|---|
| Publication Subtype | USGS Numbered Series |
| Title | Special Contributing Area Loading Program user’s manual |
| Series title | Open-File Report |
| Series number | 2024-1021 |
| DOI | 10.3133/ofr20241021 |
| Publication Date | April 26, 2024 |
| Year Published | 2024 |
| Language | English |
| Publisher | U.S. Geological Survey |
| Publisher location | Reston, VA |
| Contributing office(s) | Central Midwest Water Science Center |
| Description | Report: vi, 15 p.; Software Release |
| Online Only (Y/N) | Y |
| Additional Online Files (Y/N) | N |