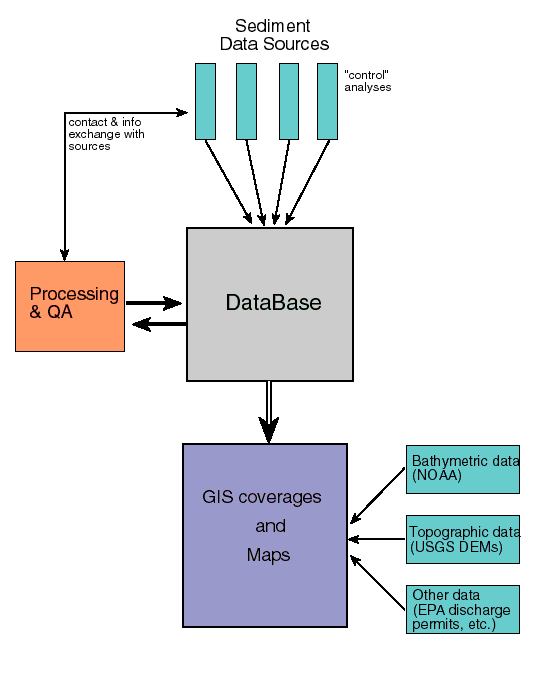
II. Sediment Database Structure and DevelopmentA. "Flat file vs. relational" database structuresWe define database terms as follows. A flat file is a collection of data organized in columns and rows, pertinent to a given subject. A data table showing various parameters from Lake Pontchartrain and surroundings (Table 1) is an example. This is the way earth scientists, who often deal with very complex systems, have traditionally collected and analyzed data. Spreadsheets like Microsoft Excel are a popular way to display, manipulate, and create plots and diagrams from flat files.
Potential confusion emerges from two interpretations of "relational database systems". A broad use of the term relational would refer to database systems that relate different data tables to each other and, therefore, are capable of querying these tables to extract information. Database management software like Microsoft Access serves this purpose in the current work (Fig. 1). However, database systems professionals commonly adopt the specific conventions of the "relational model" introduced by E.F. Codd of the IBM corporation in 1970 (Walters, 1987, p.46), taking the definition one step farther. This model uses formal mathematical rules of set theory and relational algebra to arrange the tables and their relationships in a manner that prevents anomalies from occurring while inserting, updating or deleting data. The guidelines for this system, called "normalization", require that every row (tuple) have a primary key; the attributes in a relational table must depend on the primary key; and the nonkey attributes in the table must be independent of each other. In other words, complex data systems are broken up into their most fundamental relationships to form tables, each of which must have a primary key, and which generally have less than 25 fields (columns). An example of such a relational system (with minor modifications) applied to sediment chemistry is provided in Figure 2 and Table 2 (data from the U.S. Environmental Protection Agency’s EMAP program). This system allows computer database managers to manipulate very large and complex databases with flexibility and efficiency. Normalized tables are essential in a very large database, especially one containing data that requires frequent updating. A table which is not normalized may contain data that is dependent on other data or entries that are repeated. This causes significant difficulties in maintaining the internal consistency (integrity) of the database while updating the data. The disadvantage of removing all dependencies is that these may be the principle features that scientists use to compare and analyze data. Although such relationships could be stored or recreated in query structures, this process may require services of professional or experienced database managers. For smaller databases, it may be possible to reduce the need for such expertise and recombination of data by keeping the database structure in formats convenient to the main user needs. "Horizontal" vs. "Vertical" format The Pontchartrain database (containing about 90,000 descriptors and measurements) uses a mixed databasing system. It departs from the classical relational model by allowing multiple dependent fields. However, this kind of structure is not a problem since the data are essentially static. The majority of the updates involve adding new records but not changing what already has been entered. The structure displays the parameters in a "horizontal" format, meaning the chemical constituents are the field names stretching across the table horizontally (Table 3). Such structures differ from the format used in Table 2 which shows the chemical constituents listed vertically in one column, repeating for each station. The horizontal format allows the scientist to more conveniently view, compare, sort and associate data that intuitively belong together. The tables may have hundreds of fields rather than be limited to a few tens of fields as in the vertical format, but the horizontal format obviously requires a fewer number of records. Database Mangagement System (DBMS) software like Microsoft Access is nearly unlimited in the number of records it can manage (2 billion per table), but the latest version of Microsoft Excel only allows 65,536 records. The horizontal table structure allows storage and use in both Excel and Access. Even though they are related by a unique identification number and can be queried by DBMS software, some computer specialists may still refer to the tables as flat files because of the horizontal format which is not normalized.
|
||||||||||||