
| Lake Pontchartrain Basin: Bottom Sediments and Related Environmental Resources |
DATABASE STRUCTURE AND DEVELOPMENT
Flat file versus relational database structures
We define database terms as follows. A flat file is a collection of data organized in columns and rows, pertinent to a given subject. A data table showing various parameters from Lake Pontchartrain and surroundings (table 1) is an example. This is the way earth scientists, who often deal with very complex systems, have traditionally collected and analyzed data. Using spreadsheets like Microsoft® Excel is a popular way to display, manipulate, and create plots and diagrams from flat files.
| Relational databases |  Figure 1. Example of database query |
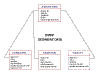 Figure 2. EMAP table relationships |
Potential confusion emerges from two interpretations of "relational database systems". A broad use of the term relational would refer to database systems that relate different data tables to each other and, therefore, are capable of querying these tables to extract information. Database management software like Microsoft® Access serves this purpose in the current work (fig. 1). However, database systems professionals commonly adopt the specific conventions of the "relational model" introduced by E.F. Codd of the IBM corporation in 1970 (Walters, 1987, p. 46), taking the definition one step farther. This model uses formal mathematical rules of set theory and relational algebra to arrange the tables and their relationships in a manner that prevents anomalies from occurring while data are inserted, updated, or deleted. The guidelines for this system, called "normalization", require that every row (tuple) have a primary key, the attributes in a relational table must depend on the primary key, and the nonkey attributes in the table must be independent of each other. In other words, complex data systems are broken up into their most fundamental relationships to form tables, each of which must have a primary key, and which generally have less than 25 fields (columns). An example of such a relational system (with minor modifications) applied to sediment chemistry is provided in figure 2 and table 2 (data from the U.S. Environmental Protection Agency’s EMAP program).
This system allows computer database managers to manipulate very large and complex databases with flexibility and efficiency. Normalized tables are essential in a very large database, especially one containing data that require frequent updating. A table that is not normalized may contain data that is dependent on other data or entries that are repeated, which causes significant difficulties in maintaining the internal consistency (integrity) of the database.
The disadvantage of removing all dependencies is that these are precisely the relationships scientists use to compare and analyze data. Although database management software is designed to be able to create queries showing desired combinations of data, this action requires services of professional or experienced staff. The need for such specialized experience may be reduced by storing the data in a format deemed convenient for general users, that is, tables containing some dependencies and, consequently, not entirely normalized. This format was chosen for the Pontchartrain database because the advantages of less frequent querying and easy conversion back to a spreadsheet outweighed any drawbacks to having unnormalized tables.
"Horizontal" versus "vertical" format
The Pontchartrain database uses a mixed database system. It departs from the classical relational model by allowing multiple dependent fields. This structure is acceptable because the data are essentially static. The majority of the updates involve adding new records but not changing what already has been entered. The structure displays the parameters in a "horizontal" format, meaning the chemical constituents are the field names stretching across the table horizontally (table 3). Such structures differ from the format used in table 2, which shows the chemical constituents listed vertically in one column, repeating for each station. The horizontal format allows the scientist to more conveniently view, compare, sort, and associate data that intuitively belong together. The tables may have hundreds of fields rather than be limited to a few tens of fields as in the vertical format, but the horizontal format obviously requires a fewer number of records. The latest version of Microsoft® Excel allows a maximum of 65,536 records, but Database Mangagement System (DBMS) software like Microsoft® Access is much less limited in the number of records it can manage (maximum size of a table is 1 gigabyte). The horizontal table structure allows storage and use in both Excel and Access. Even though they are related by a unique identification number and can be queried by DBMS software, some still refer to the tables as flat files because of the horizontal format, which is not normalized.
| Although the current database's total storage capacity is small in comparison with industrial or agency databases, it has many complex parameters and properties. The development and interactive use of the database throughout both the data processing and interpretative phases (fig. 3) offer parallels to large industrial database systems with their feedback loops to data sources and customers. Industrial managers now use "data mining" to perform statistical analysis and modeling techniques to uncover patterns and relationships hidden in an organization's database (Edelstein, 1998). This intelligent data querying and exploration of data resources helps to uncover new relationships rather than merely to provide answers to standard queries, as traditional databases have done. Data mining likewise implies the necessity for continuous modification of database structures, another feature of the present work. | 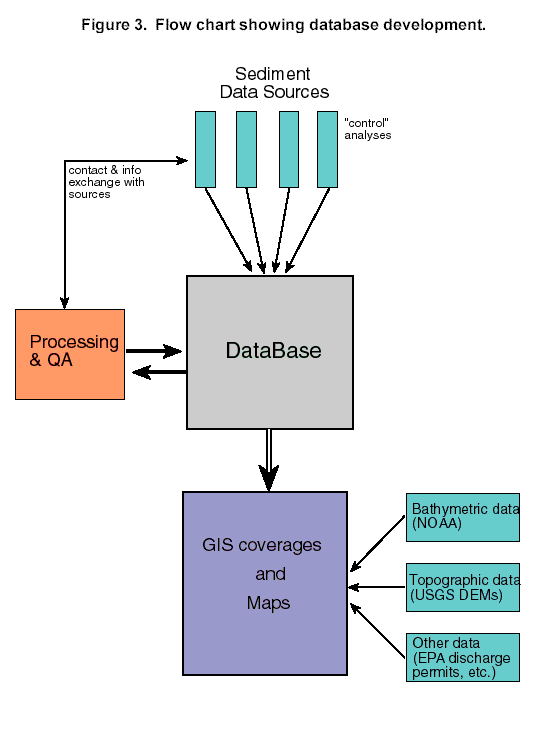 Figure 3. Flow chart showing database development
Figure 3. Flow chart showing database development |
| Forward to Data
Dictionary |
|
Table of Contents: Sediment Database and Geochemical Assessment |
|